※内容は2025/11/3時点で実行確認できている手順です。記載している情報は随時上書きアップデートしていますので、あらかじめご了承ください。
※Intel N100搭載PCでTVサーバーを作る記事を作成しました。TVサーバーを構築するならKonomiTVもインストールできるIntel N100系の方がおすすめです。
—
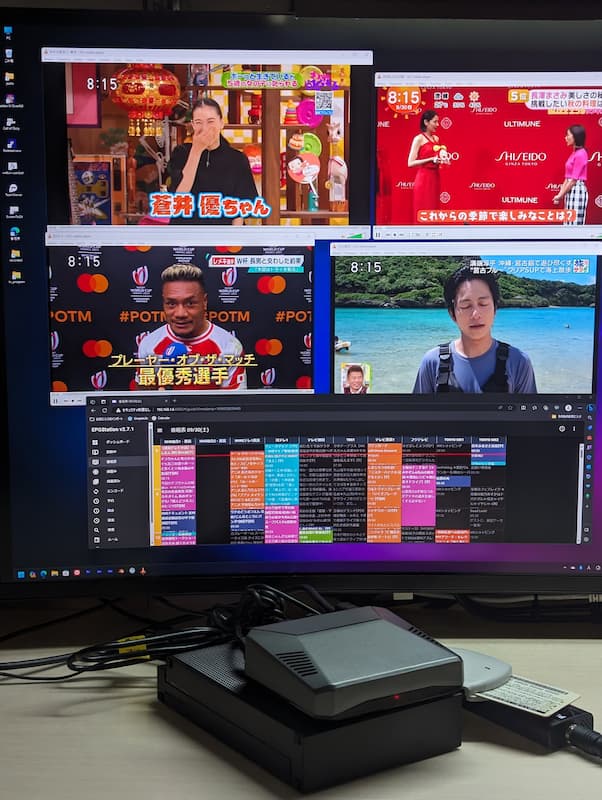
HDDレコーダーが壊れたことを期に、RaspberryPi 4で地デジ4ch+BS4ch同時TV録画サーバーを仕立て上げました。RaspberryPiでTV録画サーバを組むと、一ヶ月程度運用するだけで以下のようなメリットがあることが実感できます。
4chの地デジ録画と4chBS録画(同時録画はRaspberryPiの処理性能の制限で計6chまで)が可能
録画データを他のストレージにバックアップでき、永久保存できるようになる
録画データからCMを削除でき、MP4ファイルへ変換することで最終保存ファイルの再生時間とファイルサイズを縮小できる
録画データの再生方法に縛りがない(ミラーリングによる再生ができない、USB接続スピーカーで音声出力ができないなど)
録画ファイルを再生する際に、同時視聴・同時録画に伴う視聴制限を受けることがない
録画予約やファイル整理に専用アプリを必要とせず、ブラウザ上の広い画面で操作でき、文字の入力にPC・スマホ・タブレットのキーボードを使えるので操作性がいい
スマホやタブレットに録画番組をローカルに保持して再生できる
一度セットアップするとメンテナンスフリーでHDDレコーダー並に安定稼働する
ハード故障時の復旧時には、故障箇所のハードウェアの入れ替えのみで即復旧できる
待機電力は4〜5W、録画時も8W弱程度で消費電力が低い(電気代は概ね一ヶ月150円程度)
設置面積が市販HDDレコーダーの1/4程度で済む
録画サーバー自体は1年間放置運用した結果、強制リセットが必要な場面に遭遇することもなく動作は非常に安定しています。録画品質についてもチューナーにPX-Q3U4を使用した場合、1日4時間程度の録画頻度という条件で2ヶ月に1番組程度の割合でDropが10回程度発生する程度のDrop率でこの時も録画画像に破綻はなかったので、市販のHDDレコーダー並みの録画品質は確保できていると判断しています。
上記の理由からRaspberryPiで作る録画サーバーのメリットは絶大なので、今後市販のHDDレコーダーに戻ることはなさそうです。
しかし、RaspberryPiで録画サーバーをセットアップするために必要な設定と手順はネット上に散逸しており、古い情報も出てきたりして、後日同じ設定をしようとしても時間がかかります。そこで、検証を重ねて確定させたセットアップの最小手順、及び設定内容と設定の意味を忘れないようにここにメモしておきます。
目指すTV録画サーバー仕様について
RaspberryPiで録画サーバーを組み上げるときに選択できる機能は数多くあるので野放図に設定をすると仕様が一向に固まらず、設定に終わりが見えなくなります。そこで、ここでは下記の条件に留意しつつ設定手順を記載しています。
完全ヘッドレスで初期セットアップからメンテナンスまで行えるようにする
設定変更のトライアルに対して復旧が簡単にできるようにOSはmicroSDで運用し、外付けストレージには録画データのみを保存する
OSが書かれているmicroSDへの書き込みは極力抑え、microSDの故障率を下げるようにする
設定値はできるだけデフォルトのものを使用し、一から復旧する際の手順を単純化する
RaspberryPi上での処理はm2tsでのTV録画とSamba経由での録画データの外部転送のみとし、録画への影響を極力避けるようにCPUに負荷がかかる機能(エンコードなど)は行わない
Databaseの不整合を避けるため、録画ファイルの管理はEPG stationでのみ行い、コンソールやSamba経由での録画ファイル操作は行わない
設定については安定稼働と管理コストの最小化を最優先事項とする
準備するもの
RaspberryPiで録画サーバーを製作するにあたり、準備したものは以下のとおりです。
RaspberryPi 4(8GB)
RaspberryPi用ケース
12V 20W充電器 & USB-Cケーブル(最大電流3A対応)
SSD/HDD(USB接続外付けストレージ)
32GB 高耐久microSD
地デジ+BSチューナー
カードリーダー & B-CASカード
RaspberryPi 4
RaspberryPi 4はメモリサイズが1GB、2GB、4GB、8GBのものがあります。ネットの動作情報を見ると4GBのもので問題なく動作しているようなので、4GBのものでも動作すると思います。ただし、今後ソフトのアップデートなどでメモリを必要とすることもあるかもしれませんので、8GBのものを購入するほうが安心です。
RaspberryPi用ケース
RaspberryPi用として安価で売られている小型プラケースはファンの電源をGPIOから取っていて、冷却ファンが壊れて停止した時に急な電流値の上昇によりRaspberryPiが過電流で故障することがあります。このことから安い小型プラケースでは、年単位で常時稼働させるには心許ないです。
なお、RaspberryPi4の発熱とファンの必要性に関しては下記YouTube動画で検証してくれていて、冷却ファンでRaspberryPiを冷やしていれば問題は発生しない、すなわち冷却ファンのあるケースであれば問題ないと判断できます。
DeskPi Pro
録画用HDDをRaspberryPiと同じケースに入れて利用したい場合は、DeskPi Proがおすすめです。
https://www.seeedstudio.com/DeskPi-Pro-Set-top-Box-For-Raspberry-Pi-4-p-4704.html
DeskPi ProはHDD/SSDを内蔵できることが特徴で、映像出力端子に標準HDMIを使えるようになります。ただし、値段は1万円以上でちょっと高いです。
DeskPi Proはケース内空間に余裕があり、RaspberryPiには大きな放熱フィンが付けられ、放熱用のファンの電源はRaspberryPiからではなく、DeskPi Proの基盤からとっているので、連続運転環境用のケースとしては安心感があります。
また、DeskPi ProはHDD/SSDの内蔵位置がRaspberryPiにスタックする位置ではなく横に並べる形なので、SSDとRaspberryPi本体を離してデバイスが高熱になるのを避けられる利点もあります。SSDを内蔵できるケースは他にもありますが、RaspberryPiやSSDの発熱量を考えると内部空間に余裕があるDeskPi Proが安心です。
またDeskPi Proは電源を常時通電状態にでき、停電時復帰時には自動で再起動もかかるので、録画サーバ用途としては安心です。
録画中のファンの動作音は寝室に置いても動作しているかどうかわからないくらいでした。
Argon ONE Raspberry Pi 4 Case V2
録画用HDDにUSB接続の外付けHDDを利用する場合は、Argon ONE Raspberry Pi 4 Case V2がおすすめです。
https://argon40.com/products/argon-one-v2-case-for-raspberry-pi-4
Argon ONE Raspberry Pi 4 Case V2は安価なわりに頑丈な金属ケースで、放熱はこの金属ケースが担います。また、映像出力端子が標準サイズのHDMIなので、セットアップやトラブル時などにディスプレイを接続する場合、micro HDMIのケーブルを用意せずに済みます。
稼働中にファンが動作することはほどんどなく、録画中に寝室に置いても動作しているかどうかわからないくらいでした。
microSD
環境セットアップ後のmicro SDの使用ファイルサイズは8GB程度なので、microSDの容量は16GBあれば十分です。ここでは容量は過剰にはなりますが、32GBのものを使用しました。理由は入手性が良く価格も手頃で偽物を掴まされる危険が少ないためです。
なお、TV録画サーバーは長期間連続運用するので、熱と書き込み回数に対して耐久性のある高耐久のものが必須です。バックアップや故障に備えて2枚購入し、一枚を復旧用のバックアップディスクとして持っておくといいです。
12V 20W充電器 & USB-Cケーブル
充電器はUSB-AタイプのものがDeskPi Proに付属していますがUSB-Aタイプの充電器は規格上限が18Wのため、USB-C出力の20WのUSB-C接続充電器を別途購入した方が良さそうです。理由はUSBから電源を取る機器を接続するときに電力が足りず録画中に不調をきたす可能性があり、期待通りに録画できなくなった場合に原因特定に時間を取られるためです。
ダイソーでも700円程度で売っていますが、見えないところで常時通電するものなので、Anker製など少しでも信頼性の高いものを選択する方が安心です。
充電ケーブルは3A対応のものであれば100均のもので問題はないと思います。
録画ファイル保存用ストレージ
録画ファイル保存用ストレージは常に書き込み処理が走り常に稼働状態で故障のリスクも高いため、録画用ストレージは消耗品と考え、録画データはこまめにバックアップしておくようにします。
いつ壊れてもいいという前提で運用するので、古いPCから抜き出したHDD/SSDを再利用するといいです。録画データのファイルサイズは1時間あたり7.5GBになるため、100時間以上の録画データを保存できる様に1GB以上のHDD/SSDが使いやすいと思います。
DeskPi Proを利用する場合は機材をコンパクトにまとめるために2.5インチHDD/SSDを内蔵して運用します。DeskPi Proを利用しない場合はRaspberryPiのUSBコネクタを利用して接続しますが、外付けストレージはHDD/SSDを問わず、外部電源で動作するケースを用意する必要があります。
RaspberryPiのUSBに外付け2.5インチSDDを差した場合、電力供給が足りなくなるために数分録画している間に強制アンマウントされてしまいます。外付けケースにSSDを入れて外部から電源を取るようにした場合はこのような現象は発生しません。
なお、SSD/HDDを内蔵できるDeskPi Proは、SSD/HDDのどちらを内蔵してもケースに供給する電源のみの運用で録画に失敗することはありませんでした。
地デジチューナー
地デジ/BSチューナーは入手のしやすさや、ネット上に設定方法やトラブルシュート情報が豊富にあるという点でPLEX製のものを選択することになります。録画品質の安定性の点から、事実上の選択肢はPX-W3U4かPX-Q3U4の2択と思います。
当初はPX-Q1UDを購入て録画しましたが、PX-Q1UDはチューナーごとに受信品質が異なる、複数録画すると特定チャンネルでドロップが発生するなど録画品質を一定に保つことが困難なため、PX-Q3U4に乗り換えました。PX-Q3U4は4ch同時録画でドロップもほぼ発生することもなく安定動作しています。
ただし、PX-W3U4は内蔵ファンの音がかなり大きく静かな場所ではかなり耳障りな音を発するため、今は天井裏に録画サーバーを移動して騒音対策をしています。
もし、リビングや寝室など居住スペースに設置する必要がある場合は、PX-Q3U4のファンを自分で外してしまうか、地デジ1chのみになりますがPX-S1UDが良いと思います。
カードリーダー & B-CASカード
PX-W3U4にはB-CASカードリーダーが内蔵されていますが、Raspberry Piはこの内蔵カードリーダーを使えないため、別途B-CASカード用のカードリーダーを接続する必要があります。
カードリーダーはネット上に設定方法が豊富にあるSCR3310を利用するのが一番安心できますが、ネット上で動作確認されているものであればなんでもいいと思います。
B-CASカードについては古いテレビやHDDレコーダーのものを取り出して利用します。2160円でB-CASカードを入手する方法もあるようですが、購入未経験のため入手方法や注意事項については他のHPを参照してください。
アンテナ分波器・分配器
壁に2口のアンテナ出力があればいいですが、少ない場合は購入しましょう。なお、チューナーに直接アンテナケーブルを挿す場合、ケーブルが硬いとチューナーが軽すぎて位置が定まらなくなるのでケーブルの柔らかい分配器・分波器を挟むとケーブルの取り回しがよくなります。
実際に購入したもの
参考までに購入時の注文画面のキャプチャを貼っておきます。
ハードウェア組み立て
ケースにRaspberryPiを取り付ける
説明書に従って接続し、ネジ止めすれば大丈夫です。ネジが多くあるので、無くさないように小皿を準備しておくと良いです。
ネットワーク接続方法
無線LAN接続では録画データをコピーするときの転送速度が遅すぎるため、ネットワーク接続は有線LAN接続一択です。
RaspberryPi OSをセットアップする
セットアップはディスプレイがなくてもできますが、できるだけディスプレイは接続しておいた方がいいです。ディスプレイに起動メッセージが表示されるので、エラーがある場合にすぐに対処ができ、手戻りの発生を防げます。
動作確認ができたあとにディスプレイを外して安定動作確認をする方が、トラブルシュート時の効率がいいです。
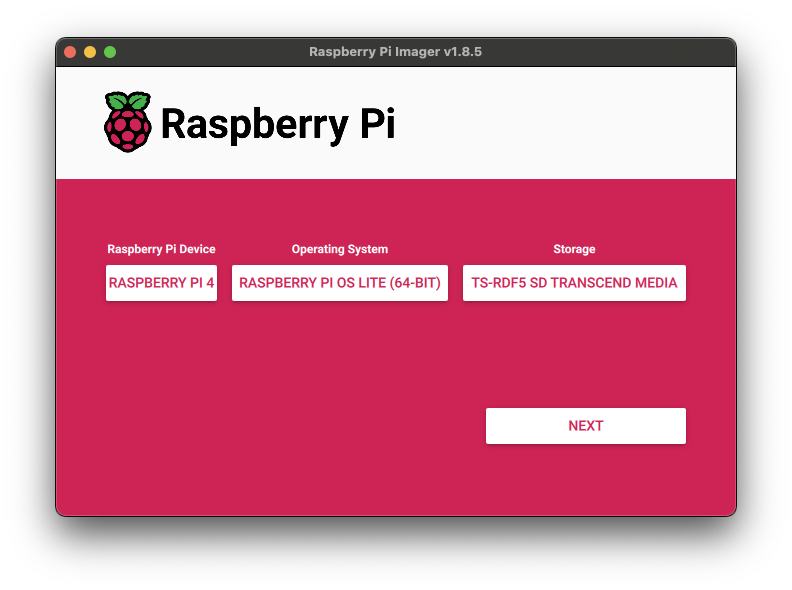
SDカードにRaspberryPi OSをインストールする
まずmicroSDをPCに挿して認識させます。
OSは「RASBERRY PI OS LITE(64-BIT)」を選択し、Storageには差し込んだmicroSDを選択して「NEXT」ボタンを押します。
すると下記のようなダイアログが表示されるので「EDIT SETTING」を選択し、初回起動時のデフォルト設定をします。
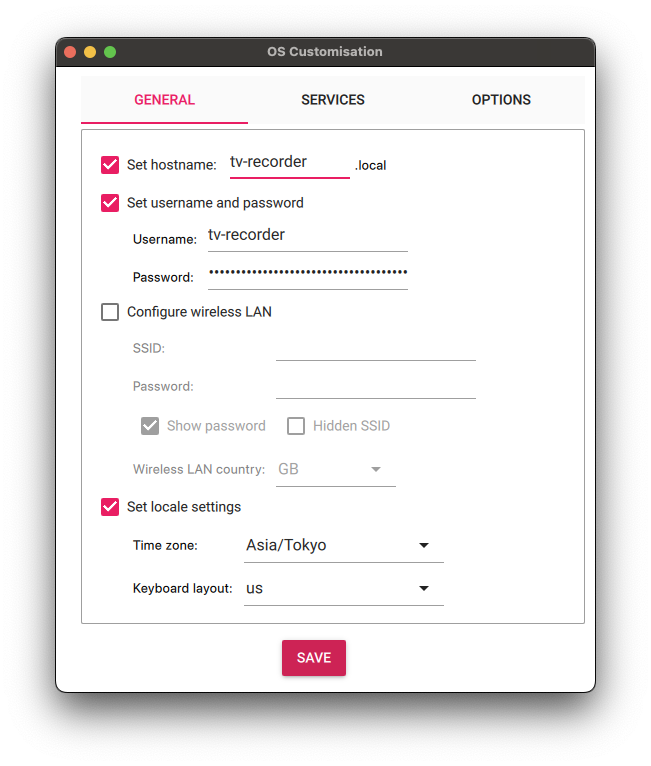
username(ユーザーアカウント名)はセキュリティの観点からデフォルトの’pi’は使用せず、’tv-recorder’としています。以降、ユーザーアカウント名は’tv-recorder’として記載します。
設定完了後に「YES」を押すと書き込みが始まり、2分程度で書き込みとVerifyが完了します。
書き込みが完了したら、microSDをRaspberryPiに差し込み電源を入れます。すると数回の再起動の後にログインプロンプトが画面に表示されます。
IPアドレスを固定する
IPアドレスを固定することで再セットアップ時の手間を減らせますが、RaspberryPi側でIPを固定すると再セットアップ時の手間が増えるので、DHCPで常に固定IPが渡されるように設定します。
RaspberryPiのMACアドレスはifconfigコマンドで確認できます。
$ ifconfig
...
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST > mtu 1500
inet 192.168.1.6 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::dc18:4126:573c:59b prefixlen 64 scopeid 0x20<link >
ether d8:3a:dd:47:0b:50 txqueuelen 1000 (イーサネット)
RX packets 10003268 bytes 703917092 (671.3 MiB)
RX errors 0 dropped 2 overruns 0 frame 0
TX packets 55536584 bytes 83569019440 (77.8 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
....Code language: HTML, XML ( xml ) この作業はヘッドレスではできませんが、一度この設定をしてしまえば以降は完全ヘッドレスでセットアップができるようになります。
ログインパスワード無しでssh接続できるようにする
録画サーバーの設定やメンテナンス時にはssh経由でログインすることが多々ありますが、その度にパスワードを入力するのはかなりの手間です。この入力をスキップするためにSSH公開鍵認証でログインできるようにします。
まずログインするPC上で秘密鍵キーを以下のコマンドで作成します。
$ ssh-keygen -t ed25519実行が完了すると、秘密鍵と公開鍵がそれぞれ~/.ssh/id_ed25519と~/.ssh/id_ed25519.pubに生成されます。
次にPC上で以下のコマンドを実行し公開鍵をRaspberryPiに転送します。このときパスワードの入力を求められるので、tv-recorderのパスワードを入力します。
$ ssh-copy-id -i ~/.ssh/i d_ed25519.pub tv-recorder@192.168 .1 .xxxCode language: JavaScript ( javascript ) これでRaspberryPiにログインする時のパスワード入力が不要になります。
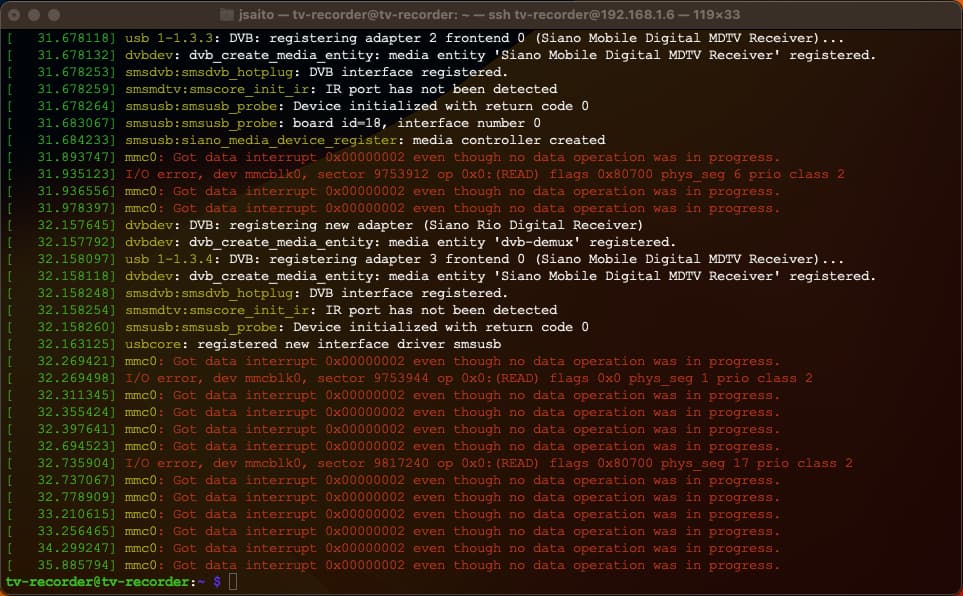
Kernel起動時にエラーが出ていないかを確認する
RaspberryPiにsshでログインしたら、dmesgコマンドで起動時にKernelが致命的なエラーを吐いていないかを確認しましょう。
例えばmicroSDカードに異常がある場合、dmesgの表示は以下のようになります。このmicroSDカードをOSディスクにした時は再起動時にカーネルパニックが頻発しました。この場合はmicroSDを交換して対応します。
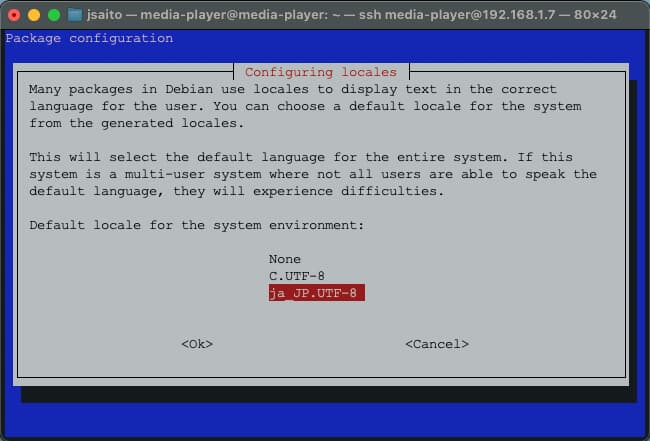
ロケールを日本語に変更する
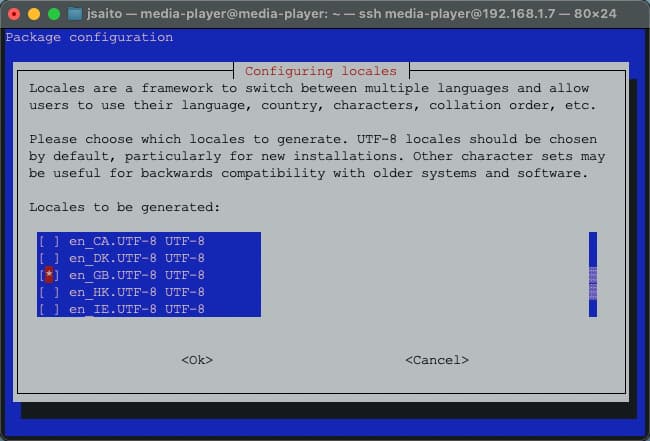
RaspberryPiのデフォルトロケールは’en-GB.UTF-8’です。録画ファイルのファイル名は日本語で表記されるため、このままではファイルリストを表示したときなどにファイル名が文字化けしてしまい、各種作業の確認が困難になります。日本語表記のファイル名が正しく表示できるようにするため、ロケールを’ja-JP.UTF8’に変更します。
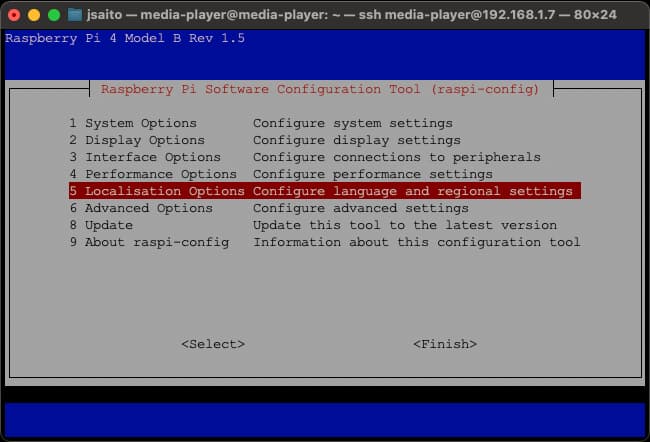
変更には下記コマンドを実行して、ロケールを変更します。
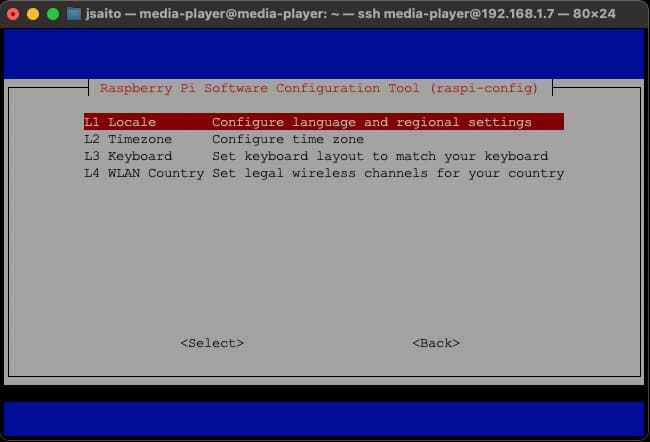
$ sudo raspi-configCode language: Bash ( bash ) RasPi configが起動したら、’5. Localisation Option > L1. Locale’を選択します。
Package configuration画面が表示されたら、’en_GB.UTF-8’のチェックを外し、’jp_JP.UTF-8’にチェックを入れ、OKを選択します。
RasPi configをクローズする際にデフォルトロケールの選択画面が表示されるので、’ja_JP.UTF-8’を選択してOKを選択します。
ロケール変更が終わったら、.bashrcの最終行にロケール宣言を追記します。
$ vi ~/.bashrc
---
...
export LC_CTYPE=ja_JP.UTF-8
...必須ソフトをインストール・アップデートする
下記コマンドを実行してaptのパッケージリストをアップデートします。
$ sudo apt update
$ sudo apt upgrade -yCode language: Bash ( bash ) 下記コマンドを実行してgitなどセットアップに必要なソフトをインストールします。
$ sudo apt-get install nodejs cmake g++ git curl unzip gcc makeCode language: Bash ( bash ) 下記コマンドを実行してvimをアップデートします。
$ sudo apt --purge remove vim-common vim-tiny
$ sudo apt install vim
$ vi --version
VIM - Vi IMproved 9.1 (2024 Jan 02, compiled May 23 2025 00:48:59)
...Code language: Bash ( bash ) 録画データのフォルダ名・ファイル名は日本語になるため、コマンドラインでの録画ファイルの整理はかなりの手間になります。この問題を解決するため、FDもインストールしておきます。
$ sudo apt-get install fdcloneCode language: JavaScript ( javascript ) また、意図せずにディスクがいっぱいになったときにディスクを占有しているファイルやフォルダを特定できるようにするため、ncduもインストールしておきます。
$ sudo apt-get install ncduCode language: JavaScript ( javascript ) RaspberryPiケースのドライバをインストールする
【Desk Pi Proの場合】
下記コマンドを実行してファンのコントロール用ドライバをインストールします。インストーラーを実行すると再起動がかかり、ファンが停止していることがわかります。
$ cd ~
$ git clone https:
$ cd ~/deskpi/i nstallation/RaspberryPiOS/64 bit/
$ sudo ./install-raspios-64 bit.shCode language: JavaScript ( javascript ) ファンの動作温度についてはCPUクーラーを搭載しファンで空冷もしているので、デフォルト値で良いと思います。
【Argon ONE PI4 V2の場合】
下記コマンドを実行して’Argon ONE PI4 V2 Power button & Fan control’をインストールします。実行後、常に動作していたファンの音がしなくなることが確認できます。
$ curl https:Code language: JavaScript ( javascript ) argonone-configでCPUの温度ごとにファンの速度を変えることができますが、これはデフォルトのままで良さそうです。
室温28度の条件下でCPU温度を計測したところ、何も動作させていない状態で42-45度、4ch同時録画中で52度くらいでした。ArgonOneの設定値は55度で10%、60度で55%、65度で100%でファンが駆動する設定で、CPUクロック低下は80度を超えた時ですので、デフォルト値で十分と判断しています。
Swapを無効化する
microSDへの書き込みを抑止してmicroSDを保護するため、下記コマンドを実行してSwapファイルによる書き込みを抑止します。
まず、SwapファイルがmicroSDに書かれるかどうかをswaponコマンドでチェックします。
$ swapon --show
NAME TYPE SIZE USED PRIO
/dev/zram0 partition 2G 0B 100上記のようにzramでSwapが動作している場合はRAM上にSwapが作られるため無効化は不要です。zramでない場合は下記コマンドでswapファイルの作成を抑止します。
$ sudo swapoff --all
$ sudo systemctl stop dphys-swapfile
$ sudo systemctl disable dphys-swapfile設定完了後、下記コマンドを実行してSwapが作成されなくなったことを確認しましょう。
$ free -h
total used free shared buff/cache available
Mem: 7.6Gi 141Mi 7.3Gi 1.0Mi 216Mi 7.4Gi
Swap: 0B 0B 0BCode language: Bash ( bash ) ログ出力先をRAMに変更する
microSDへの書き込みを減らすために/var/logへの書き込み先をRAMに変更するlog2ramをインストールします。
$ wget https:
$ tar xf log2ram.tar.gz
$ cd log2ram-master
$ sudo ./install.shCode language: JavaScript ( javascript ) インストールが完了したらRespberry Piを再起動し、dfコマンドでlog2ramが動作していることを確認しましょう。
$ df
Filesystem 1K-blocks Used Available Use% Mounted on
...
log2ram 131072 14632 116440 12% /var/log
...Code language: Bash ( bash ) ※’sudo apt install log2ram’でインストールする手順が各種サイトで紹介されていますが、Rasberry Pi Lite(64bit)では起動時にエラーが出て動作しないため、上記手順でインストールする必要があります。
タイムゾーンを変更する
下記コマンドを実行してタイムゾーンを日本に変更します。
$ sudo timedatectl set -timezone Asia/TokyoCode language: JavaScript ( javascript ) HDD/SSDをセットアップする
ここでは外付けSSD/HDDをフォーマットして読み書きができるようにセットアップする方法を記載します。バックアップ・入れ替え時の手間・運用時の柔軟性の観点から、セットアップは1パーティション構成としています。
HDD/SSDを接続してOSが認識できることを確認する
まず外付けストレージをUSBで接続します。次に下記コマンドを実行して、RaspberryPi OS上からHDD/SSDが見えていることを確認します。
$ sudo fdisk -l
...
Disk /dev/sda: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: MQ01ABD100
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
... もし接続したHDD/SSDが表示されていない場合は、接続に問題がない、故障していないかなどを確認し、正しく表示されるようにする必要があります。
HDD/SSDの既存のパーティションを削除する
すでに作成されているパーティションがある場合は'fdisk -l'コマンド実行時に下記のように/dev/sda1~のように追加情報が表示されます。
$ sudo fdisk -l
...
Disk /dev/sda: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: TOSHIBA MQ01ABD1
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xd940675f
Device Boot Start End Sectors Size Id Type
/dev/sda1 2048 1048578047 1048576000 500G 83 Linux
/dev/sda2 1048578048 1953525167 904947120 431.5G 83 Linux
...この場合は下記のようにfdiskでdコマンドを実行して既存のパーティションを削除します。
$ sudo fdisk /dev/sda
Welcome to fdisk (util-linux 2.36 .1 ).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): d
Partition number (1 ,2 , default 2 ): 1
Partition 1 has been deleted.
Command (m for help): d
Selected partition 2
Partition 2 has been deleted.
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Code language: JavaScript ( javascript ) HDD/SSDのパーティションを作成する
下記コマンドを実行してHDD/SSDをフォーマットします。一旦運用が始まるとパーティションのサイズの調整はできないのでパーティションは切らずHDD/SSD全体を1パーティションとします。
$ sudo fdisk /dev/sda
Welcome to fdisk (util-linux 2.36 .1 ).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (1 -4 , default 1 ):
First sector (2048 -1953525167 , default 2048 ): 2048
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048 -1953523120 , default 1953523120 ): 1953523120
Created a new partition 1 of type 'Linux' and of size 931.5 GiB.
Partition
Command (m for help): w
The partition table has been altered.Code language: PHP ( php ) wコマンド実行時に実際にパーティションが作成されます。実行後にfdiskコマンドでパーティションができたかを確認します。
$ sudo fdisk -l /dev/sda
Disk /dev/sda: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: TOSHIBA MQ01ABD1
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xa615109d
Device Boot Start End Sectors Size Id Type
/dev/sda1 2048 1953523120 1953523120 931.5G 83 Linux作成したパーティションをフォーマットする
下記コマンドでHDD/SDDをext4でフォーマットします。/dev/sda1の部分はフォーマット対象のHDD/SSDのデバイス名に置き換えて実行します。コマンド実行時に確認メッセージは表示されないため、デバイス名を間違えないように気をつけましょう。 フォーマットは10秒程度で完了します。
$ sudo mkfs.ext4 /dev/sda1
mke2fs 1.46 .2 (28 -Feb-2021 )
Creating filesystem with 13107200 4 k blocks and 3276800 inodes
Filesystem UUID: 7e24 b26f-0e1 e-41 fb-8812 -b5a7522c592d
Superblock backups stored on blocks:
32768 , 98304 , 163840 , 229376 , 294912 , 819200 , 884736 , 1605632 , 2654208 ,
4096000 , 7962624 , 11239424
Allocating group tables: done
Writing inode tables: done
Creating journal (65536 blocks): done
Writing superblocks and filesystem accounting information: doneCode language: JavaScript ( javascript ) HDD/SSDを自動マウントする
/etc/fstabを編集し、再起動時に’/mnt/tv-recorderにHDD/SSDをマウントするように設定します。
まず、下記コマンドでマウントポイントを作成します。
$ sudo mkdir -p /mnt/tv-recorder
$ sudo chmod 777 /mnt/tv-recorder
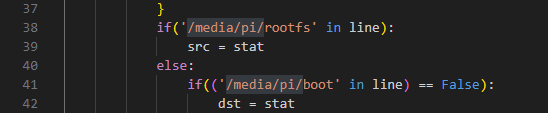
$ sudo chown -R tv-recorder:tv-recorder /mnt/tv-recorder/etc/fstab で起動時にマウントさせるため、HDD/SSDのパーティションのID(PARTUUID)を調べます。
$ sudo blkid
...
/dev/sda1: UUID="61cc9c24-b882-9949-88c8-88eab12b1ce5" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="432802cd-a1c7-ab4c-aeee-10bdddde3212"
......Code language: JavaScript ( javascript ) /etc/fstabにエントリを追加します。
$ sudo vi /etc/fstab
---
proc /proc proc defaults 0 0
PARTUUID=47e8465 b-01 /boot vfat defaults 0 2
PARTUUID=47e8465 b-02 / ext4 defaults,noatime 0 1
PARTUUID=61 cc9c24-b882-9949 -88 c8-88 eab12b1ce5 /mnt/tv-recorder ext4 defaults,nofail 0 0 Code language: PHP ( php ) 再起動して自動マウントされることを確認します。
$ df
Filesystem 1 K-blocks Used Available Use% Mounted on
...
/dev/sda1 960302824 297730032 613718332 1 % /mnt/ tv-recorder
...Code language: JavaScript ( javascript ) 自動マウントされていることが確認できたら'touch /mnt/tv-recorder/testfile'コマンドでファイルが書けるかを確認しましょう。
Sambaサーバーをインストールする
Windows PCから録画ファイルを読めるように、sambaをインストールします。操作ミスで録画ファイルを消さないようにread onlyをyesにしておき、ファイル操作は全てEPG stationからでしかできないようにします。
$ sudo apt install samba samba-common-bin下記コマンドを実行し、smbアカウントを追加します。
$ sudo smbpasswd -a tv-recorder/etc/samba/smb.confに以下を追加します。
$ sudo vi /etc/samba/smb.conf
---
...
[tv-recorder]
path = /mnt/ tv-recorder/
public = yes
guest ok = yes
read only = yes
force user = tv-recorder
comment=EPG stationCode language: JavaScript ( javascript ) smb.confを書き換えた場合は下記コマンドでsambaサーバーを再起動する必要があります。
$ sudo systemctl restart smbd再起動したら他のPCからRaspberryPiのrecordedフォルダにアクセスできることを確認します。
カードリーダー/TVチューナーをセットアップする
カードリーダーを接続する
RaspberryPi上のUSB2.0ポートに接続します。カードリーダーはUSB1.0として認識されるため、USB 3.0ポートへの接続は無意味です。
次に下記コマンドを実行してドライバをインストールします。
$ sudo apt install -y libpcsclite-dev pcscd pcsc-tools libccidカードリーダーにB-CASカードを挿入し、下記コマンドを実行してB-CASカードが正しく認識されていることを確認します。カード挿入時はIC面が上になるよう、カードの向きに注意しましょう。
$ sudo pcsc_scan
...
Japanese Chijou Digital B-CAS Card (pay TV)
...pcsc_scanコマンドは自動終了しないため、上記メッセージを確認できたらCTRL-Cで強制終了します。以降このドライバは使用しないため、サービスを停止しておきます。
$ sudo systemctl stop pcscd.socket
$ sudo systemctl disable pcscd.socket
Removed "/etc/systemd/system/sockets.target.wants/pcscd.socket" .Code language: JavaScript ( javascript ) TVチューナーを接続する
TVチューナーはRaspberryPi上のUSB2.0ポートに接続します。TVチューナーはUSB 2.0として認識されるため、USB3.0ポートへの接続は無意味です。
【PX-Q3U4の場合】
ドライバインストール方法ググるとpx4_drvが表示されますが、本家のpx4_drvではインストールができないため、つくみ島だより でリリースされているFork版をインストールします。
https://github.com/tsukumijima/px4_drv?tab=readme-ov-file
上記解説の通りにコマンドを実行すればインストール完了です。以下に実行したコマンドを列挙します。
$ sudo apt install dkms
$ sudo apt-get -y install raspberrypi-kernel-headers
$ git clone https:
$ cd ~/px4_drv/fwtool
$ make
$ wget http:
$ unzip -oj pxw3u4_BDA_ver1x64.zip pxw3u4_BDA_ver1x64/PXW3U4.sys && rm pxw3u4_BDA_ver1x64.zip
$ ./fwtool PXW3U4.sys it930x-firmware.bin && rm PXW3U4.sys
$ sudo mkdir -p /lib/firmware && sudo cp it930x-firmware.bin /lib/firmware/
$ cd ~/px4_drv/driver/
$ make
$ sudo make install
$ cd ~/px4_drv
$ wget https:
$ sudo cp -a ./ /usr/src/px4_drv-0.4 .5
$ sudo dkms add px4_drv/0.4 .5
$ sudo dkms install px4_drv/0.4 .5 Code language: PHP ( php ) このタイミングでPX-Q3U4のLEDが点灯しファンが回り出します。インストール完了後に下記コマンドを実行して、下記のような出力が表示されればOKです。
$ sudo modprobe px4_drv
$ lsmod | grep -e ^px4_drv
px4_drv 143360 0【PX-Q1UDの場合】
PX-U1DXはRaspberryPiに20W電源を接続している場合、バスパワーで問題なく動作することを確認しているため、TVチューナーに付属している電源を接続する必要はありません。
また、電源を接続しているとチューナー側からUSBポートを通して電力が供給されるため、再起動時に接続されたハードウェアが完全にリセットされる保証がなく、トラブル時の原因の切り分けが難しくなりますので、電源は外しておいた方が無難です。
※電源無しで動作することは公式に保証しておらず、私の環境で問題がないことを確認しているだけですので、動作不安定な場合には電源を接続して、問題が改善するかどうか確認しましょう。
PX-Q1UDのドライバはRaspberryOSにデフォルトでインストールされており、接続した直後からPX-S1UDが4つとして認識されていますが、このドライバでは起動時にファイル不足のエラーが吐かれていることがdmesgで確認できEPGデータも取得できないことを確認しているので、下記コマンドを実行して公式サイトにあるドライバをインストールします。
$ wget http:
$ unzip PX-S1UD_driver_Ver.1 .0 .1 .zip
$ sudo cp PX-S1UD_driver_Ver.1 .0 .1 /x64/amd64/isdbt_rio.inp /lib/firmware/Code language: JavaScript ( javascript ) ドライバインストール後にPX-S1UDを接続したままRaspberry Piを再起動し、下記コマンドを実行してPX-Q1UDが認識されていることを確認しましょう。
$ dmesg | grep PX-
[ 2.792753] usb 1-1.2.1: Product: PX-S1UD Digital TV Tuner
[ 2.980706] usb 1-1.2.2: Product: PX-S1UD Digital TV Tuner
[ 3.164841] usb 1-1.2.3: Product: PX-S1UD Digital TV Tuner
[ 3.348650] usb 1-1.2.4: Product: PX-S1UD Digital TV Tuner
$ ls -al /dev/dvb*
total 0
drwxr-xr-x 6 root root 120 Sep 30 01:47 .
drwxr-xr-x 18 root root 4220 Sep 30 01:47 ..
drwxr-xr-x 2 root root 100 Sep 30 01:47 adapter0
drwxr-xr-x 2 root root 100 Sep 30 01:47 adapter1
drwxr-xr-x 2 root root 100 Sep 30 01:47 adapter2
drwxr-xr-x 2 root root 100 Sep 30 01:47 adapter3TVチューナーが認識されていない場合は、ディスプレイを繋いでTVチューナー接続時にエラーが出ていないか確認しましょう。エラーが出ている場合はリブートすると¥。
Docker版mirakurun-epgstationをインストールする
現時点でメンテナンスが継続されていて、かつI/Fが最も洗練されているのはEPG stationです。現在Docker版でメンテナンスが進んでいます。しかし、そのままではPX-Q3U4では利用できないため、DockerコンテナをPX-Q3U4に設定してビルドして対応します
Dockerをインストールする
まず下記コマンドを実行してDockerをインストールします。
$ sudo curl -sSL https:
...
$ sudo usermod -aG docker $USER
$ docker --version
Docker version 28.5 .1 , build e180ab8
$ docker compose version
Docker Compose version v2.40 .3 Code language: PHP ( php ) Docker版EPG Stationをインストールする
基本的な手順は以下のサイトを参考にし、現状に合わせて実行コマンドとオプションをアップデートしています。
ビルド環境を整える
まず、下記コマンドを実行して、dockerコンテナのビルド環境を整えます。
$ cd ~
$ git clone https:Code language: PHP ( php ) Configurationファイルをコピーする
まずファイルをテンプレートからコピーしておきます。
$ cd ~/docker-mirakurun-epgstation
$ cp docker-compose-sample.yml docker-compose.yml
$ cp epgstation/config/config.yml.template epgstation/config/config.yml※この時点で編集済みのdocker-compose.yml,epgstation/config/config.ymlがある場合はこちらをコピーをしておくことで復旧の手間を省くことができます
次にログファイルのConfigurationをコピーします。
$ cp epgstation/config/operatorLogConfig.sample.yml epgstation/config/operatorLogConfig.yml
$ cp epgstation/config/epgUpdaterLogConfig.sample.yml epgstation/config/epgUpdaterLogConfig.yml
$ cp epgstation/config/serviceLogConfig.sample.yml epgstation/config/serviceLogConfig.ymldocker-compose.ymlを編集する
はじめにカードリーダのデバイス番号を確認します。BusとDeviceの番号でデバイスファイルを特定できます。下記の例では/dev/bus/usb/001/003がカードリーダーのデバイスファイルになります。
$ lsusb
...
Bus 001 Device 003: ID 04e6:5116 SCM Microsystems, Inc. SCR331-LC1 / SCR3310 SmartCard Reader
...【PX-Q3U4の場合】
docker-compose.ymlを以下のように書き換えます。
$ vi ~/docker-mirakurun-epgstation/docker-compose.yml
---
version: '3.7'
services:
mirakurun:
image: chinachu/mirakurun
cap_add:
- SYS_ADMIN
- SYS_NICE
ports:
- "40772:40772"
- "9229:9229"
volumes:
- ./mirakurun/conf:/app-config
- ./mirakurun/data:/app-data
- ./mirakurun/run:/var /run
- ./mirakurun/opt:/opt
environment:
TZ: "Asia/Tokyo"
devices:
- /dev/bus:/dev/bus
- /dev/px4video0:/dev/px4video0
- /dev/px4video1:/dev/px4video1
- /dev/px4video2:/dev/px4video2
- /dev/px4video3:/dev/px4video3
- /dev/px4video4:/dev/px4video4
- /dev/px4video5:/dev/px4video5
- /dev/px4video6:/dev/px4video6
- /dev/px4video7:/dev/px4video7
- /dev/bus/usb/001 /003
restart: always
logging:
driver: json-file
options:
max-file: "1"
max-size: 10 m
mysql:
image: mariadb:10.5
volumes:
- mysql-db:/var /lib/mysql
environment:
MYSQL_USER: epgstation
MYSQL_PASSWORD: epgstation
MYSQL_ROOT_PASSWORD: epgstation
MYSQL_DATABASE: epgstation
TZ: "Asia/Tokyo"
command: --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --performance-schema=false --expire_logs_days=1
restart: always
logging:
options:
max-size: "10m"
max-file: "3"
epgstation:
build:
context: "./epgstation"
dockerfile: "debian.Dockerfile"
volumes:
- ./epgstation/config:/app/config
- ./epgstation/data:/app/data
- ./epgstation/thumbnail:/app/thumbnail
- ./epgstation/logs:/app/logs
- /mnt/tv-recorder/backup:/app/backup
- /mnt/tv-recorder/recorded_files/keep:/app/keep
- /mnt/tv-recorder/recorded_files/no_conversion:/app/no_conversion
- /mnt/tv-recorder/recorded_files/delete:/app/delete
- /mnt/tv-recorder/recorded_files/delete_after_watch:/app/delete_after_watch
- /mnt/tv-recorder/droplog:/app/droplog
environment:
TZ: "Asia/Tokyo"
depends_on:
- mirakurun
- mysql
ports:
- "8888:8888"
- "8889:8889"
user: "1000:1000"
restart: always
volumes:
mysql-db:
driver: local
Code language: PHP ( php ) ファイルの差分は以下のとおりです。
$ diff docker-compose.yml docker-compose-sample.yml
14 ,15 d13
< - ./mirakurun/run:/var /run
< - ./mirakurun/opt:/opt
20 ,29 c18
< - /dev/px4video0:/dev/px4video0
< - /dev/px4video1:/dev/px4video1
< - /dev/px4video2:/dev/px4video2
< - /dev/px4video3:/dev/px4video3
< - /dev/px4video4:/dev/px4video4
< - /dev/px4video5:/dev/px4video5
< - /dev/px4video6:/dev/px4video6
< - /dev/px4video7:/dev/px4video7
< - /dev/bus/usb/001 /003
---
> - /dev/dvb:/dev/dvb
65 ,70 d54
< - /mnt/tv-recorder/backup:/app/backup
< - /mnt/tv-recorder/recorded_files/keep:/app/keep
< - /mnt/tv-recorder/recorded_files/no_conversion:/app/no_conversion
< - /mnt/tv-recorder/recorded_files/delete_after_watch:/app/delete_after_watch
< - /mnt/tv-recorder/droplog:/app/droplog
<
78 c63
< user: "1000:1000"
---
> Code language: PHP ( php ) 【PX-Q1UDの場合】
docker-compose.ymlを以下のように書き換えます。
$ vi ~/docker-mirakurun-epgstation/docker-compose.yml
---
version: '3.7'
services:
mirakurun:
image: chinachu/mirakurun
cap_add:
- SYS_ADMIN
- SYS_NICE
ports:
- "40772:40772"
- "9229:9229"
volumes:
- ./mirakurun/conf:/app-config
- ./mirakurun/data:/app-data
- ./mirakurun/run:/var /run
- ./mirakurun/opt:/opt
environment:
TZ: "Asia/Tokyo"
devices:
- /dev/bus:/dev/bus
- /dev/dvb:/dev/dvb
- /dev/bus/usb/001 /003
restart: always
logging:
driver: json-file
options:
max-file: "1"
max-size: 10 m
mysql:
image: mariadb:10.5
volumes:
- mysql-db:/var /lib/mysql
environment:
MYSQL_USER: epgstation
MYSQL_PASSWORD: epgstation
MYSQL_ROOT_PASSWORD: epgstation
MYSQL_DATABASE: epgstation
TZ: "Asia/Tokyo"
command: --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --performance-schema=false --expire_logs_days=1
hentication-plugin=mysql_native_password
restart: always
logging:
options:
max-size: "10m"
max-file: "3"
epgstation:
build:
context: "./epgstation"
dockerfile: "debian.Dockerfile"
volumes:
- ./epgstation/config:/app/config
- ./epgstation/data:/app/data
- ./epgstation/thumbnail:/app/thumbnail
- ./epgstation/logs:/app/logs
- ./mirakurun/opt:/opt
- /mnt/tv-recorder/backup:/app/backup
- /mnt/tv-recorder/recorded_files/keep:/app/keep
- /mnt/tv-recorder/recorded_files/no_conversion:/app/no_conversion
- /mnt/tv-recorder/recorded_files/delete:/app/delete
- /mnt/tv-recorder/recorded_files/delete_after_watch:/app/delete_after_watch
- /mnt/tv-recorder/droplog:/app/droplog
environment:
TZ: "Asia/Tokyo"
depends_on:
- mirakurun
- mysql
ports:
- "8888:8888"
- "8889:8889"
user: "1000:1000"
restart: always
volumes:
mysql-db:
driver: local
Code language: PHP ( php ) ファイルの差分は以下のとおりです。
14 ,15 d13
< - ./mirakurun/run:/var /run
< - ./mirakurun/opt:/opt
21 d18
< - /dev/bus/usb/001 /003
57 ,61 c54
< - ./mirakurun/opt:/opt
< - /mnt/tv-recorder/backup:/app/backup
< - /mnt/tv-recorder/recorded_files/keep:/app/keep
< - /mnt/tv-recorder/recorded_files/no_conversion:/app/no_conversion
< - /mnt/tv-recorder/recorded_files/delete:/app/delete
< - /mnt/tv-recorder/recorded_files/delete_after_watch:/app/delete_after_watch
< - /mnt/tv-recorder/droplog:/app/droplog
---
> - ./recorded:/app/recorded
70 c63
< user: "1000:1000"
---
> Code language: PHP ( php ) tuners.ymlを編集する
tuners.ymlを書き換えます。
【PX-Q3U4の場合】
$ vi ~/docker-mirakurun-epgstation/mi rakurun/conf/tuners.yml
---
- name: PX-Q3U4_S1
types :
- BS
- CS
command : recpt1 --device /dev/px4video0 <channel> - -
decoder: arib-b25-stream-test
isDisabled : false
- name: PX-Q3U4_S2
types :
- BS
- CS
command : recpt1 --device /dev/px4video1 <channel> - -
decoder: arib-b25-stream-test
isDisabled : false
- name: PX-Q3U4_T1
types :
- GR
command : recpt1 --device /dev/px4video2 <channel> - -
decoder: arib-b25-stream-test
isDisabled : false
- name: PX-W3U4_T2
types :
- GR
command : recpt1 --device /dev/px4video3 <channel> - -
decoder: arib-b25-stream-test
isDisabled : false
- name: PX-W3U4_S3
types :
- BS
- CS
command : recpt1 --device /dev/px4video4 <channel> - -
decoder: arib-b25-stream-test
isDisabled : false
- name: PX-W3U4_S4
types :
- BS
- CS
command : recpt1 --device /dev/px4video5 <channel> - -
decoder: arib-b25-stream-test
isDisabled : false
- name: PX-W3U4_T3
types :
- GR
command : recpt1 --device /dev/px4video6 <channel> - -
decoder: arib-b25-stream-test
isDisabled : false
- name: PX-W3U4_T4
types :
- GR
command : recpt1 --device /dev/px4video7 <channel> - -
decoder: arib-b25-stream-test
isDisabled : false Code language: JavaScript ( javascript ) 【PX-Q1UDの場合】
$ vi ~/docker-mirakurun-epgstation/mi rakurun/conf/tuners.yml
---
- name: adapter0
types :
- GR
dvbDevicePath : /dev/ dvb/adapter0/dvr0
decoder : arib-b25-stream-test
command : dvbv5-zap -a 0 -c ./config/dvbconf-for -isdb/conf/dvbv5_channels_isdbt.conf
-r -P <channel>
isDisabled: false
- name: adapter1
types :
- GR
dvbDevicePath : /dev/ dvb/adapter1/dvr0
decoder : arib-b25-stream-test
command : dvbv5-zap -a 1 -c ./config/dvbconf-for -isdb/conf/dvbv5_channels_isdbt.conf
-r -P <channel>
isDisabled: false
- name: adapter2
types :
- GR
dvbDevicePath : /dev/ dvb/adapter2/dvr0
decoder : arib-b25-stream-test
command : dvbv5-zap -a 2 -c ./config/dvbconf-for -isdb/conf/dvbv5_channels_isdbt.conf
-r -P <channel>
isDisabled: false
- name: adapter3
types :
- GR
dvbDevicePath : /dev/ dvb/adapter3/dvr0
decoder : arib-b25-stream-test
command : dvbv5-zap -a 3 -c ./config/dvbconf-for -isdb/conf/dvbv5_channels_isdbt.conf
-r -P <channel>
isDisabled: false Code language: JavaScript ( javascript ) docker fileをビルドし起動する
下記コマンドを実行してMirakurun/EPG Stataionをビルドし起動します。ビルドには20分程度かかるのでのんびり待ちましょう。
$ cd ~/docker-mirakurun-epgstation/
$ sudo docker compose pull
$ sudo docker compose run --rm -e SETUP=true mirakurun
$ sudo docker compose up -dCode language: JavaScript ( javascript ) インストール完了後、ブラウザから'http://<IP Address>:40772/'にアクセスしてMirakrunのHPが表示され、'http://<IP Address>:8888/'にアクセスしてEPG Stationが表示されることを確認します。
録画コマンドをインストールする【PX-Q3U4の場合のみ必要】
下記コマンドを実行して録画コマンドrecpt1をdockerコンテナ上でコンパイルし~/docker-mirakurun-epgstation/mirakurun/opt/bin/へインストールします。docker上でコンパイルしないとglibcのバージョン違いが原因でコマンドが動作しないため、Docker上でコンパイルし、コンパイルした実行ファイルを~/docker-mirakurun-epgstation/mirakurun/opt/bin/へインストールします。
$ sudo docker container exec docker-mirakurun-epgstation-mirakurun-1 apt-get update
$ sudo docker container exec docker-mirakurun-epgstation-mirakurun-1 apt-get upgrade -y
$ sudo docker container exec docker-mirakurun-epgstation-mirakurun-1 apt-get install -y --no-install-recommends make gcc g++ pkg-config pcscd libpcsclite-dev libccid pcsc-tools
$ sudo docker container exec docker-mirakurun-epgstation-mirakurun-1 apt-get -y install build-essential libtool autoconf git automake wget cmake
$ sudo docker container exec docker-mirakurun-epgstation-mirakurun-1 sh -c 'git clone https://github.com/stz2012/recpt1 /tmp/recpt1 && cd /tmp/recpt1/recpt1 && ./autogen.sh && ./configure && make && make install && mkdir -p /opt/bin && cp -f /tmp/recpt1/recpt1/recpt1 /opt/bin && cp -f /tmp/recpt1/recpt1/recpt1ctl /opt/bin && cp -f /tmp/recpt1/recpt1/checksignal /opt/bin && rm -rf /tmp/recpt1'Code language: JavaScript ( javascript ) 下記コマンドを実行して録画ファイルができることを確認します。ここで録画したファイルはTS抜きはされていないのでファイルを再生しても録画した番組は表示されません。
$ ~/docker-mirakurun-epgstation/mi rakurun/opt/bin/recpt1 --device /dev/px4video0 BS15_0 10 bs0.m2ts
$ ~/docker-mirakurun-epgstation/mi rakurun/opt/bin/recpt1 --device /dev/px4video1 BS01_2 10 bs1.m2ts
$ ~/docker-mirakurun-epgstation/mi rakurun/opt/bin/recpt1 --device /dev/px4video2 BS15_0 10 bs0.m2ts 27 10 gr0.m2ts
$ ~/docker-mirakurun-epgstation/mi rakurun/opt/bin/recpt1 --device /dev/px4video3 BS15_0 10 bs0.m2ts 27 10 gr1.m2ts
$ ~/docker-mirakurun-epgstation/mi rakurun/opt/bin/recpt1 --device /dev/px4video4 BS15_0 10 bs0.m2ts
$ ~/docker-mirakurun-epgstation/mi rakurun/opt/bin/recpt1 --device /dev/px4video5 BS01_2 10 bs1.m2ts
$ ~/docker-mirakurun-epgstation/mi rakurun/opt/bin/recpt1 --device /dev/px4video6 BS15_0 10 bs0.m2ts 27 10 gr0.m2ts
$ ~/docker-mirakurun-epgstation/mi rakurun/opt/bin/recpt1 --device /dev/px4video7 BS15_0 10 bs0.m2ts 27 10 gr1.m2tsCode language: JavaScript ( javascript ) チャンネルスキャンをする
下記コマンドを実行してチャンネルスキャンを実行します。スキャンは10分程度で完了します。
$ curl -X PUT "http://localhost:40772/api/config/channels/scan" Code language: JavaScript ( javascript ) 実行しなくてもEPG stationで番組が表示されますが、一部チャンネル(TOKYO MXなど)が表示されないことがあること、再取得処理が延々と続きプロセスを圧迫することがあり、録画が突然停止することもあるため、未実施の場合は必ず実行しましょう。
再起動時にEPG stationが起動しない問題への対応
上記機材と手順でセットアップを完了させるとReboot後にEPG stationが表示されないことがあります。この時にプロセスを確認するとMirakrunが起動していないことがわかります。
$ ps -ax | grep docker-proxy
1410 ? Sl 0:00 /usr/sbin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 9229 -container-ip 172.18.0.2 -container-port 9229
1916 ? Sl 0:00 /usr/sbin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 8889 -container-ip 172.18.0.3 -container-port 8889
1931 ? Sl 0:00 /usr/sbin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 8888 -container-ip 172.18.0.3 -container-port 8888
2283 pts/0 S+ 0:00 grep --color=auto docker-proxyCode language: Bash ( bash ) Mirakurunが動作している場合は下記のプロセスが表示されますが、これがありません。
1397 ? Sl 0:00 /usr/sbin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 40772 -container-ip 172.18.0.2 -container-port 40772Code language: Bash ( bash ) この現象が発生してもsshログインして手動で再起動はできるので、systemdを利用してOS起動後に遅延処理を実行してdockerを再スタートするように設定を追加して、リブート時に確実にEPG Stationが起動するように対応します。
再起動用のスクリプトを書く
まず下記スクリプトを作成して/home/tv-recorderに置きます。chmod 777で実行権限を付与し、再起動処理が正しく動作することを確認します。
#!/bin/bash
pushd /home/tv-recorder/docker-mirakurun-epgstation
sudo docker compose restart
popdOS起動後に再起動処理を実行するように設定する
遅延実行にはsystemdを利用します。まずepgstation.serviceとepgstation.timerファイルを下記手順で作成します。
$ sudo vi /etc/systemd/system/epgstation.service
---
[Unit]
Description=Restart EPG station
[Service]
ExecStart=/home/tv-recorder/restart_epgstation.sh
[Install]
WantedBy=multi-user.target
---Code language: Bash ( bash ) $ sudo vi /etc/systemd/system/epgstation.timer
---
[Unit]
Description=EPG station restart timer
[Timer]
OnBootSec=30sec
Unit=epgstation.service
[Install]
WantedBy=multi-user.target
---Code language: Bash ( bash ) 待ち時間は20秒ではdockerのリスタートされず、30秒で安定してリスタートがかかったことから30秒に設定しています。
次に下記コマンドを実行してepgstation.timerをsystemdに登録します。
$ sudo systemctl enable epgstation.timer動作を確認する
上記のすべての設定が完了したらRaspberryPiを再起動して、EPG Stationが起動することと、視聴や録画が正しくすることを確認してください。
【参考】EPG Stationをカスタマイズする
ここではdocker-compose.ymlとepgstation/config/config.ymlを編集して、EPG Stationの録画用ディスク構成や録画ファイル名などを設定する方法を記載します。この2つのymlを設定後にバックアップをとっておくことで次回の設定の手間を省くことができます。
録画データを分類するためのフォルダを作成する
録画データの分類用フォルダは以下のように設定しました。
‘no_conversion’ -> mp4への変換不要の番組(ニュースなど)
‘delete’ -> 期限が来たら削除する(バラエティ番組など)
‘delete_after_watch’ -> 視聴したら削除する(ドラマなど)
‘keep’ -> ずっと残す(取っておいて何度も見たい映画・アニメなど)
さらにSDデータのbackup用のフォルダも用意します。
$ sudo mkdir -p /mnt/tv-recorder/backup /mnt/tv-recorder/recorded_files/delete /mnt/tv-recorder/recorded_files/delete_after_watch /mnt/tv-recorder/recorded_files/keep /mnt/tv-recorder/recorded_files/no_conversion
$ sudo chmod -R 777 /mnt/tv-recorder
$ sudo chown -R tv-recorder:tv-recorder /mnt/tv-recorderCode language: JavaScript ( javascript ) Dockerから外付けストレージにアクセスできるように設定する
録画ファイルの保存先として以下のディレクトリを指定できるようにdocker-conpose.ymlを修正します。
/mnt/tv-recorder/recorded_files/keep
/mnt/tv-recorder/recorded_files/delete_after_watch
/mnt/tv-recorder/recorded_files/delete
/mnt/tv-recorder/recorded_files/no_conversion
$ cd ~
$ vi docker-mirakurun-epgstation/docker-compose.yml
---
services:
...
epgstation:
...
volumes:
...
(修正前)
- ./recorded:/app/ recorded
(修正後)
- /mnt/ tv-recorder/backup:/app/ backup
- /mnt/ tv-recorder/recorded_files/keep:/app/ keep
- /mnt/ tv-recorder/recorded_files/no_conversion:/app/ no_conversion
- /mnt/ tv-recorder/recorded_files/delete :/app/ delete
- /mnt/ tv-recorder/recorded_files/delete_after_watch:/app/ delete_after_watchCode language: JavaScript ( javascript ) 設定が完了したらdockerを再起動し、dockerコンテナから/mnt/tv-recorder以下にマウントしたbackup,recorded,tentativeディレクトリにアクセスできるようになったことを確認します。docker inspectコマンドで指定するContainer IDは起動ごとに動的に変化するため、psコマンドで確認する必要があります。
$ cd ~/docker-mirakurun-epgstation
$ sudo docker compose down
$ sudo docker compose up -d
$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
562 d4973e9d5 docker-mirakurun-epgstation_epgstation "npm start" 10 days ago Up 35 hours 0.0 .0 .0 :8888 -8889 ->8888 -8889 /tcp docker-mirakurun-epgstation_epgstation_1
dd8371eb9ce9 chinachu/mirakurun "docker-entrypoint.s…" 10 days ago Up 36 hours 0.0 .0 .0 :9229 ->9229 /tcp, 0.0 .0 .0 :40772 ->40772 /tcp docker-mirakurun-epgstation_mirakurun_1
d6b9da403421 mariadb:10.5 "docker-entrypoint.s…" 10 days ago Up 36 hours 3306 /tcp docker-mirakurun-epgstation_mysql_1
$ sudo docker inspect 562 d4973e9d5
...
{
"Type" : "bind" ,
"Source" : "/mnt/tv-recorder/backup" ,
"Destination" : "/app/backup" ,
"Mode" : "rw" ,
"RW" : true ,
"Propagation" : "rprivate"
},
{
"Type" : "bind" ,
"Source" : "/mnt/tv-recorder/recorded_files/no_conversion" ,
"Destination" : "/app/no_conversion" ,
"Mode" : "rw" ,
"RW" : true ,
"Propagation" : "rprivate"
},
{
"Type" : "bind" ,
"Source" : "/mnt/tv-recorder/recorded_files/keep" ,
"Destination" : "/app/keep" ,
"Mode" : "rw" ,
"RW" : true ,
"Propagation" : "rprivate"
},
{
"Type" : "bind" ,
"Source" : "/mnt/tv-recorder/recorded_files/delete_after_watch" ,
"Destination" : "/app/delete_after_watch" ,
"Mode" : "rw" ,
"RW" : true ,
"Propagation" : "rprivate"
},
{
"Type" : "bind" ,
"Source" : "/mnt/tv-recorder/recorded_files/delete" ,
"Destination" : "/app/delete" ,
"Mode" : "rw" ,
"RW" : true ,
"Propagation" : "rprivate"
},
...Code language: PHP ( php ) 録画ファイルの保存パスとデフォルト録画ファイル名を変更する
まず、ファイル名を'YYYYMMDD_HHMM <番組名>'に変更します。
$ cd ~
$ vi docker-mirakurun-epgstation/epgstation/config/config.yml
---
...
(修正前)
recordedFormat : '%YEAR%年%MONTH%月%DAY%日%HOUR%時%MIN%分%SEC%秒-%TITLE%'
(修正後)
recordedFormat : '%YEAR%%MONTH%%DAY%_%HALF_WIDTH_TITLE%'
...Code language: JavaScript ( javascript ) さらに録画データの保存先を’自動削除する'(delete)、’保存する'(keep)で指定できるように、下記のように変更します。
設定ではHDDの容量が50GBを切った場合に、自動で古いものからファイルを削除するようにしています。EPG stationは保存先によらず単純に古い録画データから消していく仕様のようなので、削除開始の閾値は全て同じにする方が動作がわかりやすくなります。
$ cd ~
$ vi docker-mirakurun-epgstation/epgstation/config/config.yml
---
...
(修正前)
recorded :
- name: recorded
path : '%ROOT%/recorded'
(修正後)
recorded :
- name: '自動削除する'
path : '%ROOT%/delete'
limitThreshold : 50000
action : remove
- name: '見たら消す'
path : '%ROOT%/delete_after_watch'
limitThreshold : 50000
action : remove
- name: '保存する'
path : '%ROOT%/keep'
limitThreshold : 50000
action : remove
- name: '録画のみ'
path : '%ROOT%/no_conversion'
limitThreshold : 50000
action : removeCode language: JavaScript ( javascript ) 容量が足りなくなる前に常に手動で消す方法でもいいですが、削除する量が足りない、削除忘れなどのヒューマンエラーで容量不足になるリスクがあることから、自動削除で対応する方が良いかと思います。保存期間を長くしたい場合はHDD/SSDの容量を大きくすればいいだけですので対応も簡単です。
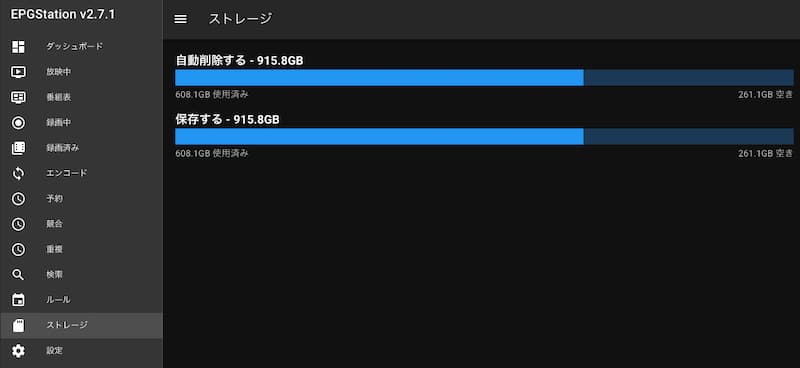
修正後にEPGStationを再起動し、EPGStationのメニューの’ストレージ’を選択して保存先が正しく認識され、録画可能な容量がHDDサイズになっていることを確認します。
$ cd ~/docker-mirakurun-epgstation
$ sudo docker compose restart録画データの所有者IDをtv-recorderに変更する
デフォルトの録画ファイルの所有者はrootになっており、sudoで実行しないと録画ファイルの移動や削除ができません。この手間を解消するため、ファイルの所有者がtv-recorderになるようにconfig.ymlに’uid: 1000′(1000はtv-redcorderのUID)を追加します。
$ cd ~
$ vi docker-mirakurun-epgstation/epgstation/config/config.yml
---
...
uid: 1000
gid: 1000
...Code language: Bash ( bash ) droplogを記録する
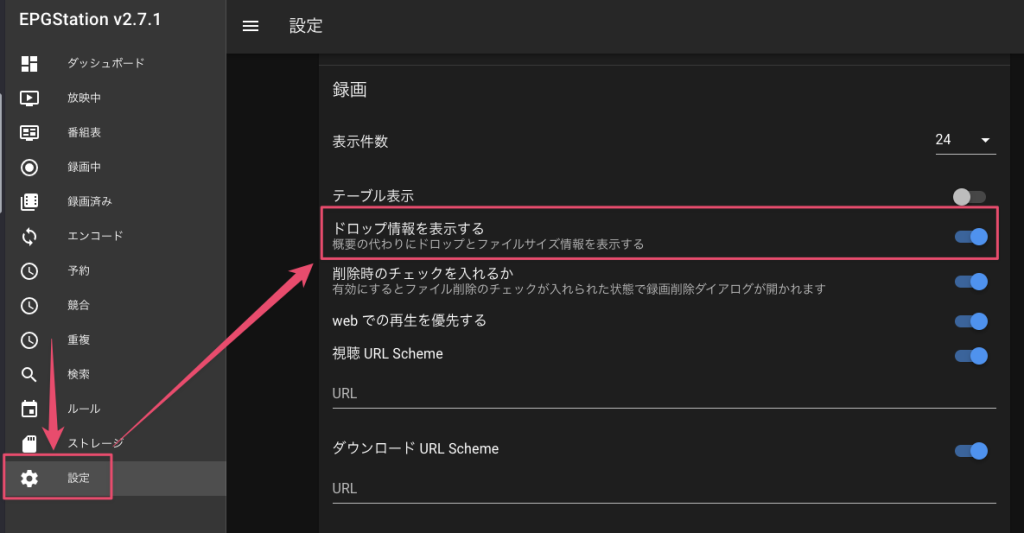
録画ファイルのクオリティ(ドロップ数)を確認できるようにするために、ダッシュボード表示時にドロップ数などの情報を表示するように設定します。
まず、droplogの格納場所を作成します。
$ sudo mkdir -p /mnt/tv-recorder/droplog
$ sudo chmod -R 777 /mnt/tv-recorder/droplog
$ sudo chown -R tv-recorder:tv-recorder /mnt/tv-recorder/droplog次にdroplogを記録するようにepgstationに設定を追加します。
$ cd ~
$ vi docker-mirakurun-epgstation/docker-compose.yml
---
services:
...
epgstation:
...
volumes:
...
- /mnt/ tv-recorder/droplog:/app/ droplog 【追加】
---
$ vi ~/docker-mirakurun-epgstation/ epgstation/config/config.yml
---
...
isEnabledDropCheck: true 【追加】
dropLog : '/app/droplog' 【追加】
...Code language: JavaScript ( javascript ) 編集が終わったらEPG Stationを再起動します。
$ cd ~/docker-mirakurun-epgstation
$ sudo docker compose down
$ sudo docker compose up -dダッシュボードでドロップ情報を表示するように設定を変更します。
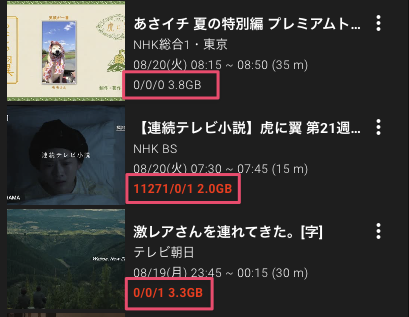
以上の設定で下記のようにドロップ情報が表示されるようになります。
【参考】docker containerでshellを起動する
docker上で起動する実行ファイルをコンパイルするときなどにterminalと同様のコマンドで実行する場合は、下記コマンドを実行してdocker container上のshellを起動することで、docker container上で各種コマンドを実行できます。
$ docker compose exec epgstation bash再生環境セットアップ
再生環境セットアップにはKonomi TV を利用します。Konomi TVはブラウザで再生するタイプのプレイヤーでPCやスマホなどにソフトをインストールする必要がないので、TV再生用ソフトとしては現時点でベストです。
Raspberry Pi上にインストールするにはKonomi TVが必要とするファイルをインストールし、Konomi TVインストーラー実行時の指示に従っていけばインストールが完了します。
node.js・pm2・lshwのインストール
Konomi TVインストールにはnode.js・pm2・lshwが必要ですが、Raspberry Pi OSパッケージにはデフォルトではインストールされていないため、下記コマンドを実行してインストールします。
$ curl -sL https://deb.nodesource.com/setup_18.x | sudo bash -
$ sudo apt install -y nodejs
$ sudo npm install -g pm2
$ sudo apt install lshwKonomi TVインストール
下記コマンドを実行してインストーラをダウンロードして実行します。
$ wget https://github.com/tsukumijima/KonomiTV/releases/download/v0.12.0/KonomiTV-Installer-ARM.elf
$ chmod a+x KonomiTV-Installer-ARM.elf
$ ./KonomiTV-Installer-ARM.elfKonomi TVのインストーラは非常に簡潔にできていますので、インストーラー実行後の説明はここでは割愛します。
ffmpegをハードウェアエンコード対応のものに入れ替える(未完了)
※Konomi TVが利用するffmpegの入れ替え方法は調査中のため、コンパイル完了までの手順をメモとして記載しておきます。
Konomi TVでインストールされるffmpegはRaspberry Piのハードウェアエンコードに対応していません。また、ソフトエンコードではRaspberry Pi 4の処理性能では解像度を320pまで落とさないと再生が停止してしまいます。
そこで、下記コマンドを実行してRapberry Piのハードウェアエンコード対応したffmpegをビルドします。コンパイルには1時間近くかかりますので、実行時には待ち時間に注意しましょう。
$ cd ~
$ git clone https://git.ffmpeg.org/ffmpeg.git ffmpeg
$ cd ffmpeg
$ ./configure --prefix=/opt && make
$ sudo make install
$ /opt/bin/ffmpeg -version
ffmpeg version N-120374-ge29016a9de Copyright (c) 2000-2025 the FFmpeg developers
built with gcc 12 (Debian 12.2.0-14+deb12u1)
configuration: --prefix=/opt
libavutil 60. 6.100 / 60. 6.100
libavcodec 62. 8.100 / 62. 8.100
libavformat 62. 1.103 / 62. 1.103
libavdevice 62. 0.100 / 62. 0.100
libavfilter 11. 3.100 / 11. 3.100
libswscale 9. 0.100 / 9. 0.100
libswresample 6. 0.100 / 6. 0.100※あとはKonomi TVのffmpegを入れ替えれば終わりですが、調査中なのでここでは割愛します。
動作確認
まず再起動したあとにdmesgコマンドで表示されるカーネルログで致命的なエラーが出力されていないかを確認しましょう。私の環境ではエラーは出力されませんでした。
次に、30分程度電源を入れっぱなしにして放置したあとにEPG stationの番組表を表示し、利用するすべてのチャンネルの番組表が表示されていることを確認しましょう。表示されない場合はアンテナ接続やMirakurunの動作(http://<IP address>:40772)などを確認しましょう。
次にEPG stationから4番組同時録画を1時間程度実行し、録画データをVLCで再生してみてノイズがないことを確認しましょう。
あとは継続使用をしてトラブルに見舞われたら随時対応と対策を打つようにします。
トラブルシュートの欄に記載した電波強度とエラーブロックの発生状況を知るツールをあらかじめ用意しておくと、ブロックノイズ発生時に原因の特定がスムースに行えます。
リモート視聴
Talescaleを使用して外部からアクセスできるようにすることで、宅内と同様に操作することができます。Talescaleの設定方法は簡単でネットに情報が多く載っていますので、ここでの設定方法は割愛します。
ルーターに穴を開けて視聴する方法は法に触れるようですので、VPN経由でアクセスする方法が安心安全です。
録画データのバックアップとmp4への変換
下記に別記事としてまとめましたので、こちらを参照してください。
microSDカードとEPG stationのデータのバックアップとリストア
microSDカード
microSDカードをRaspberryPiのOSディスクにしていると、microSDのイメージファイルを作ることで全く同じOSディスクを複製できます。OSのイメージファイルさえ持っていれば、設定の変更によりレコーダーの動作が安定しない状態に陥っても、イメージファイルからmicroSDカードを複製して入れ替えれば完全に元通りにすることができます。
イメージ作成はddコマンドでもできますが、使用している容量にかかわらずmicroSDのサイズ分のイメージデータができてしまいます。すなわち64GBのmicroSDを使用している場合は、実際に使用している容量にかかわらず64GBのイメージが出来上がります。
このサイズを縮小するために以下のサイトにあるスクリプトを利用させてもらっています。https://dev.classmethod.jp/articles/raspberrypi-compress-backup/
このスクリプトはRaspberryPi OS DesktopでユーザーIDがpiに設定されている環境で正常に動作するので、ログインユーザー名が違う場合は下記のハイライト部分を修正する必要があります。
吸い出したSDカードイメージはRaspberryPiの/mnt/tv-recorder/backup領域に保存しておき、SDカードが壊れた時にここからイメージファイルを取り出して、SDカードをすぐに復旧できるようにしておきましょう。
イメージファイルをmicroSDへ書き出す際には下記のツールを利用しています。
https://github.com/dnobori/DN-Win32DiskImagerRenewal
EPG stationのデータ(録画データのメタ情報、サムネイル、録画予約など)
/mnt/tv-recorder/backupフォルダに下記のスクリプトを作成し、’chmod 777 backup.sh’で実行権限をつけて、バックアップできることを確認します。下記スクリプトはEPG stationのデータの他に、homeディレクトリと/etc以下の編集したファイルをバックアップする処理を追加してあります。
#!/bin/bash
function set_attribute()
{
sudo mkdir -p $1
sudo chmod -R a+r $1
sudo chmod -R a+w $1
sudo chown tv-recorder:tv-recorder $1
}
record_dir=/mnt/tv-recorder
backup_dir=${record_dir}/backup
#create record directory
set_attribute ${record_dir}/recorded_files/keep
sudo touch ${record_dir}/recorded_files/keep/.keep
set_attribute ${record_dir}/recorded_files/delete
sudo touch ${record_dir}/recorded_files/delete/.keep
set_attribute ${record_dir}/recorded_files/delete_after_watch
sudo touch ${record_dir}/recorded_files/delete_after_watch/.keep
set_attribute ${record_dir}/recorded_files/no_conversion
sudo touch ${record_dir}/recorded_files/no_conversion/.keep
#create backup directory
set_attribute ${record_dir}/backup
set_attribute ${record_dir}/backup/epgstation
set_attribute ${record_dir}/backup/etc
set_attribute ${record_dir}/backup/home
# Delete empty directory
find ${record_dir}/recorded_files/ -type d -empty -exec sudo rm -rf {} \;
#backup epgstation
pushd ${backup_dir}/epgstation
sudo cp -rf database_backup database_backup_old
sudo docker exec docker-mirakurun-epgstation-epgstation-1 npm run backup /app/backup/epgstation/database_backup
set_attribute ./docker-mirakurun-epgstation/epgstation/thumbnail
cp ~/docker-mirakurun-epgstation/epgstation/thumbnail/* ./docker-mirakurun-epgstation/epgstation/thumbnail/
set_attribute ./docker-mirakurun-epgstation/epgstation/config
cp ~/docker-mirakurun-epgstation/epgstation/config/config.yml ./docker-mirakurun-epgstation/epgstation/config/
cp ~/docker-mirakurun-epgstation/docker-compose.yml ./docker-mirakurun-epgstation/
popd
#backup etc
pushd ${backup_dir}/etc
cp /etc/fstab .
mkdir -p samba
cp /etc/samba/smb.conf samba/
mkdir -p systemd/system
cp /etc/systemd/system/epgstation.* systemd/system/
popd
#backup home
sudo rsync -aP --delete /home/tv-recorder/ ${backup_dir}/home/
次に夜中の1時にバックアップ処理が走るように、crontabで下記エントリを追加します。
$ crontab -e
---
0 3 * * * cd ~ && ./backup.sh -eCode language: Bash ( bash ) OS再インストール時などでEPG stationを再構築した時は、下記コマンドを実行することでbackupファイルからリストアできます。
$ sudo docker exec docker-mirakurun-epgstation-epgstation-1 npm run restore /app/backup/epgstation/database_backup
$ cp /mnt/tv-recorder/backup/epgstation/docker-mirakurun-epgstation/epgstation/thumbnail/* ~/docker-mirakurun-epgstation/epgstation/thumbnail/ 録画データ
録画データは前述の変換スクリプトでWindows PCにバックアップされます。
EPGStationの録画予約の同期
拙宅では2台のRasberryPi録画サーバーが動いており、一台は録画専用サーバー、もう一台はリアルタイム視聴用と録画専用サーバーダウン時のバックアップサーバーとして動作させています。
このときに問題になるのが、録画予約情報の同期です。録画専用サーバーで録画予約を追加・変更したときにもう一台のサーバーにも同じ予約をいれるのは面倒で、予約を間違うと録画していたつもりが録画されていない事態にもなります。
このような事態を避けるために、夜中にスクリプトを自動実行して同期をとるように設定します。
同期にはバックアップ時に生成されるdatabaseファイルをバックアップサーバーへ転送し、バックアップサーバーのEPGStationへ反映する方法をとります。データベースの転送にはscpを利用しますが、パスワードの入力を省略するため、バックアップサーバーの公開鍵を録画サーバーにコピーしておく必要があります。
$ ssh-keygen -t ed25519
$ ssh-copy-id -i ~/.ssh/i d_ed25519.pub tv-recorder@192.168 .1 .xxxCode language: JavaScript ( javascript ) あとは、下記スクリプトをcrontabで毎日実行すれば常に録画サーバーの予約情報がバックアップサーバーに反映されます。毎時55分くらいに設定すればバックアップサーバー側で録画情報の反映の遅れが原因による録画ミスが減ると思います。
#!/bin/bash
scp 192.168.1.xxx:/mnt/tv-recorder/backup/epgstation/database_backup /mnt/tv-recorder/backup/epgstation/database_backup_for_sync
sudo docker exec docker-mirakurun-epgstation-epgstation-1 npm run restore /app/backup/epgstation/database_backup_for_sync
rm /mnt/tv-recorder/backup/epgstation/database_backup_for_sync$ crontab -e
---
0 4 * * * cd ~ && ./sync_epgstation_database.sh -eTips & Troubleshooting
ここでは、初めてRaspberryPiで録画サーバーをセットアップしたときに躓いたところや、動作確認の際に調べたことをメモしておきます。
停電復帰時に自動で再起動しない
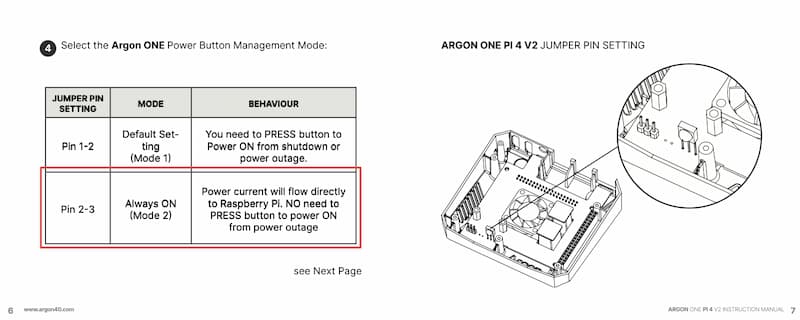
DeskPiとArgon ONEは停電などで一度電源が落ちると電源が復旧しても電源ボタンを押すまでRaspberryPiには電源が供給されません。このため、一旦停電が発生すると手動で電源をONするまで、録画が止まってしまいます。
DeskPiとArgon ONEは常時通電設定もできますので、停電対策には常時通電状態に設定を変更します。
ただし、電源ボタンによるRaspberryPiの電源ON/OFFができなくなるので、強制リセットなどで電源を一旦切る場合は電源を物理的に切断する必要があります。
同時録画ができない
Mirakurunのページを開いて、下記のPidの数値が上がっている場合は録画開始時に録画プロセスが死んでおり、RaspberryPiへの電源供給が足りていないために発生するようです。20W以上の供給能力を持つ充電アダプタをつけましょう。
CrontabでEPG stationのデータだけがバックアップできない
バックアップスクリプトを手動で実行した場合はバックアップできるにもかかわらず、Crontabで動作させるとdocker内のEPG stationのデータだけがバックアップされない場合があります。
この場合はdocker execコマンドに-itオプションがついているので、-itオプションを削除して対応します。
(正) $ sudo docker exec -it epgstation-v2.6.20 npm run backup /app/recorded/_backup/epgstation_database_backup
(誤) $ sudo docker exec epgstation-v2.6.20 npm run backup /app/recorded/_backup/epgstation_database_backupEPGは取得できるがTV放送が表示されない
B-CASカードがきちんと挿さっていない場合に発生します。再生状態でカードリーダーのLEDが動作中を示しているか確認し、点灯していない場合は挿入し直しましょう。
トラブル解析時にEPG stationのLogを見たい
下記コマンドでログのリアルタイム出力を確認できます。
$ sudo docker compose logs -f mirakurun
$ sudo docker compose logs -f mysql
$ sudo docker compose logs -f epgstation録画後数分経つと録画が停止してしまう
USBからの電源供給で動作するHDD/SSDを接続している場合に発生します。
データを記録中にピーク電流が発生したとき、動作電力が足りず強制的にUSBが抜かれた状態になるために発生するようです。電力消費が少ないSSDであってもこの現象は発生します。外部電源で動作するストレージを利用しましょう。
なお、DeskPi Proは内部で電源が別扱いになっているため、内蔵のHDD/SDDに記録していても問題なく動作します。
KonomiTVでテレビを見ているとプチフリーズ(または再生停止)する
スペックの低いタブレットなどでKonomiTVを使用してテレビを見ているとTV再生中にプチフリーズが発生したり、再生が停止したりすることがあります。調べてみるとEPG情報を取得するタイミングでプチフリーズが発生しているようです。
そこで下記のようにEPGの取得間隔を24時間に伸ばし、EPG情報更新発生のタイミングを減らせばフリーズをなくすことができます。
$ vi ~/docker-mirakurun-epgstation/mirakurun/conf/server.yml
---
programGCInterval: 86400000 # イベント情報ガベージコレクション間隔を24時間に
epgGatheringInterval: 86400000 # EPGを更新した後の休止時間を24時間に編集が終わったらEPG Stationを再起動します。
$ cd ~/docker-mirakurun-epgstation
$ sudo docker compose down
$ sudo docker compose up -d以上、参考になれば幸いです。