※2024年9月になってこのXML版は動作はしなくなりました。現在はJSON版をアップデートしていますので、XML版をご利用の方はメンテナンスを継続しているJSON版への切り替えをお願いいたします。
英会話能力の維持のために、NHKラジオ英会話をmp3化してスマホにダウンロードし、通勤途中などに聞くことを日課にしています。
ラジオ英会話はテレビやネットとは違い、聞いて理解してもらう形で構成されているため、通勤時の流し聞きにぴったりです。また、1日15分、1週間で1時間(金曜は月-木の復習回)なので、毎日1週間分を繰り返し聞くのもちょうど良いです。
ダウンロードするためにはいくつかのフリーソフトがありますが、私の場合はMacのアプリ形式で利用可能なラジリンガルを利用してダウンロードしていました。
しかし、最近はダウンロードするためのファイルを指定するXMLファイルが期待するフォーマットで登録されていないことにより、ラジリンガルを含む多くのツールでダウンロードできない事態が頻発しています。
ダウンロード可能な期間は1週間だけのため、ツールの対応を待たずに手動でもダウンロードできるようにしておかないと落ち着きません。
そこでファイルのダウンロードの手順を調べ、自分に必要な機能のみを実装し、ダウンロードの完全自動化を実現したシンプルなPythonスクリプトを作成したので、ここにメモしておきます。
ストリーミングデータを手動でダウンロードする
自動化のためには、まず手動で最小手順を確認するのが常道です。ダウンロードのための最小手順を以下に示します。
ラジオ英会話のストリーミングデータのファイル名を取得する
まず、下記ファイルへアクセスします。
すると、下記のようなXMLファイルがダウンロードできます。各”music”タグ内のhdateに放送日、file属性にファイル名、dir属性にダウンロードURLの補完用ディレクトリパスがあるので、この組み合わせをメモします。
<musicdata>
<music title="ラジオ英会話" hdate="10月31日放送分" kouza="ラジオ英会話" code="4235516" file="22-er-4235-516" dir="mp4" nendo="2022" pgcode="F0"/>
<music title="ラジオ英会話" hdate="11月1日放送分" kouza="ラジオ英会話" code="4235517" file="22-er-4235-517.mp4" nendo="2022" pgcode="F0"/>
<music title="ラジオ英会話" hdate="11月2日放送分" kouza="ラジオ英会話" code="4235518" file="22-er-4235-518.mp4" nendo="2022" pgcode="F0"/>
<music title="ラジオ英会話" hdate="11月3日放送分" kouza="ラジオ英会話" code="4235519" file="22-er-4235-519.mp4" nendo="2022" pgcode="F0"/>
<music title="ラジオ英会話" hdate="11月4日放送分" kouza="ラジオ英会話" code="4235520" file="22-er-4235-520.mp4" nendo="2022" pgcode="F0"/>
</musicdata>Code language: HTML, XML (xml)各種ダウンロードソフトによるダウンロードが失敗する原因は、file属性が“<ファイル名>.mp4”のフォーマットに準拠していないことや、dir属性のパラメータの変更に合わせてダウンロード元のURLが変更されることに起因しているようです。上記では10月31日の部分でファイル名の拡張子がないために、ダウンロードができなくなっていたようでした。
各番組のストリーミングをmp3ファイルに変換する
ストリーミングファイルのダウンロードにはffmpegを使用します。ffmpegで下記のコマンドラインオプションで起動するとmp3ファイル形式でダウンロードできます。
ffmpeg -http_seekable 0 -i https://vod-stream.nhk.jp/gogaku-stream/<'dir'属性のフォルダ名>/<'file'属性の拡張子無しファイル名>/index.m3u8 -c:a mp3 "<mp3のダウンロードパス>"
Code language: HTML, XML (xml)下記はコマンドラインの設定例になります。
ffmpeg -http_seekable 0 -i https://vod-stream.nhk.jp/gogaku-stream/mp4/22-er-4235-516/index.m3u8 -c:a mp3 ".¥ラジオ英会話 2022年10月31日放送分.mp3"Code language: JavaScript (javascript)上記コマンドラインはffmpeg 4.4.3と5.1.2で動作を確認しています。
ダウンロード処理を自動化する
上記のダウンロード処理を自動化した方法が下記になります。
各語学番組の自動ダウンロード用Pythonスクリプト
自動化にはPythonを選びました。Windows/Mac/Linux上で同じファイルで同じ処理をさせることができることと、読みやすく修正しやすいスクリプトを書くことができるためです。下記スクリプトをUTF-8で保存し実行することで、ファイルの変更なしでWindows/Mac/Linux上のPython 3.9で動作することを確認済みです。
import os
import re
import urllib.request
import xml.etree.ElementTree as ET
import subprocess
import datetime
from enum import auto
from os.path import expanduser
import sys
def main():
#OS(実行環境)依存のパラメータをセットする
if sys.platform=='win32': #Windows
path_delimiter="\\"
today=datetime.date.today()
download_dir=".\\download_" + "{0}_CW{1}".format(str(today.year),str(today.isocalendar()[1]).zfill(2))
ffmpeg_bin=".\\win\\ffmpeg.exe"
elif sys.platform=='darwin': #Mac
path_delimiter="/"
today=datetime.date.today()
download_dir=expanduser("~")+"/Downloads/NHK語学講座"+"{0}_CW{1}".format(str(today.year),str(today.isocalendar()[1]).zfill(2))
ffmpeg_bin="./mac/ffmpeg"
else: #Linux(Synology-NAS)
path_delimiter="/"
download_dir="/volume1/music/NHK語学講座"
ffmpeg_bin="/volume1/@appstore/ffmpeg/bin/ffmpeg"
#各語学講座のlistdataflv.xmlのURL、講座名、ダウンロード完了済みかどうかをチェックするファイルサイズを定義する
url_kouza_sizes = []
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/basic0/listdataflv.xml', '小学生の基礎英語', 4801300 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/basic1/listdataflv.xml', '中学生の基礎英語【レベル1】', 7201000 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/basic2/listdataflv.xml', '中学生の基礎英語【レベル2】', 7201000 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/basic3/listdataflv.xml', '中高生の基礎英語 in English', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/kaiwa/listdataflv.xml', 'ラジオ英会話', 7201000 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/vr-radio/listdataflv.xml', 'ボキャブライダー', 2407200 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/enjoy/listdataflv.xml', 'エンジョイ・シンプル・イングリッシュ', 7201000 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/timetrial/listdataflv.xml', '英会話タイムトライアル', 4801300 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/english/business1/listdataflv.xml', 'ラジオビジネス英語', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/french/kouza/listdataflv.xml', 'まいにちフランス語【初級編】', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/french/kouza2/listdataflv.xml', 'まいにちフランス語【応用編】', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/italian/kouza/listdataflv.xml', 'まいにちイタリア語【初級編】', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/italian/kouza2/listdataflv.xml', 'まいにちイタリア語【応用編】', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/german/kouza/listdataflv.xml', 'まいにちドイツ語【初級編】', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/german/kouza2/listdataflv.xml', 'まいにちドイツ語【応用編】', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/spanish/kouza/listdataflv.xml', 'まいにちスペイン語【初級編】', 7201000 ]]
url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/spanish/kouza2/listdataflv.xml', 'まいにちスペイン語【応用編】', 7201000 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/russian/kouza/listdataflv.xml', 'まいにちロシア語【初級編】', 7201000 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/russian/kouza2/listdataflv.xml', 'まいにちロシア語【応用編】', 7201000 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/chinese/kouza/listdataflv.xml', 'まいにち中国語', 7201000 ]]
# url_kouza_sizes += [['https://www.nhk.or.jp/gogaku/st/xml/hangeul/kouza/listdataflv.xml', 'まいにちハングル講座', 7201000 ]]
# ダウンロード先のフォルダがない場合はフォルダを作成する
os.makedirs(download_dir, exist_ok=True)
#各語学講座のストリーミングデータをダウンロードする
for url_kouza_size in url_kouza_sizes:
#URL/講座名(=MP3タグ名)/ファイルサイズを格納する
url=url_kouza_size[0]
kouza=url_kouza_size[1]
size=url_kouza_size[2]
# print(f"url:{url} / kouza:{kouza} / size:{size}")
# listdataflv.xmlのコンテンツを読み出す
listdataflv_xml = download_dir+"/listdataflv.xml"
urllib.request.urlretrieve(url, listdataflv_xml)
xml_tree = ET.parse(listdataflv_xml)
os.remove(listdataflv_xml)
# 各LessonのストリーミングデータをMP3に変換してダウンロードする
for xml_element_music in xml_tree.findall("music"):
# 放送年月日と年度を取得する
month=int(re.findall(r'\d+', xml_element_music.get("hdate"))[0])
day=int(re.findall(r'\d+', xml_element_music.get("hdate"))[1])
nendo=int(xml_element_music.get("nendo"))
year=datetime.date.today().year
if (12==month):
# 放送日が12月の場合は放送日の年を年度年に設定する
year=nendo
# print(f"nendo:{nendo} / year:{year} / month:{month} / day:{day}")
#※ボキャブライダー対応
#放送年度年とダウンロード年の差が2年以上ある場合はダウンロードしない
if ( datetime.date.today().year - nendo ) > 1:
continue
#放送年度年とダウンロード年の差が1年で放送月が4-11月の場合は一ヶ月以上前のコンテンツと判断してダウンロードしない
elif ( ( datetime.date.today().year - nendo ) == 1 ) and ( 3 < month ) and ( month < 12 ):
continue
else:
#放送日とダウンロード日が1週間以上離れている、もしくはダウンロード日以降に放送予定のものはダウンロードしない
elapsed_day = ( datetime.date.today() - datetime.date(year,month,day) ).days
if ( elapsed_day < 0 ) and ( 7 < elapsed_day ):
continue
# MP3に埋め込むタグ情報をセットする
tag_title=kouza+" "+"{0}年{1}月{2}日放送分".format(year,str(month).zfill(2),str(day).zfill(2))
tag_year=nendo
tag_album=kouza+"["+str(nendo)+"年度]"
# print(f"tag_title:{tag_title} / tag_year:{tag_year} / tag_album:{tag_album}")
# MP3のダウンロードパスをセットする
download_subdir=download_dir+path_delimiter+kouza+"["+str(nendo)+"年度]"
os.makedirs(download_subdir, exist_ok=True)
download_filename=kouza+" "+"{0}年{1}月{2}日放送分".format(year,str(month).zfill(2),str(day).zfill(2))+".mp3"
download_path=download_subdir+path_delimiter+download_filename
# print(f"download_path:{download_path}")
# ストリーミングファイルのURLをセットする
download_url="https://vod-stream.nhk.jp/gogaku-stream/"
if len(xml_element_music.get("dir"))>0:
download_url+=xml_element_music.get("dir")+"/"
download_url+=os.path.splitext(os.path.basename(xml_element_music.get("file")))[0]+"/index.m3u8"
# print(f"download_url:{download_url}")
# ffmpegのダウンロード処理用コマンドラインを生成する
command_line=f"{ffmpeg_bin}" \
f" -http_seekable 0" \
f" -i {download_url}" \
f" -id3v2_version 3" \
f" -metadata artist=\"NHK\" -metadata title=\"{tag_title}\"" \
f" -metadata album=\"{tag_album}\" -metadata date=\"{tag_year}\"" \
f" -ar 44100 -ab 64k -c:a mp3" \
f" \"{download_path}\""
print(command_line)
# ダウンロード処理を実行する
if( os.path.isfile(download_path)):
# すでにダウンロード済みファイルがある場合
if( os.path.getsize(download_path)<=size ):
#ファイルサイズが想定サイズに満たないときはダウンロード処理を行う
os.remove(download_path)
subprocess.run(command_line,shell=True)
else:
# ダウンロード済みファイルがない場合
# -> ダウンロード処理を行う
subprocess.run(command_line,shell=True)
if __name__ == "__main__":
main()上記のスクリプトは、ダウンロード処理の自動化の他に以下の処理を追加しています。
- 実行環境でパラメータを自動で変更する処理を追加
- NHKラジオ英会話以外の語学講座も連続してダウンロードできるように機能を追加
- xmlのdir属性に応じてURLを変更する処理を追加
- 放送日の’年度’の記述を暦年で表記できるように処理を追加
- mp3のalbum,title,yearタグに講座情報を追加
- ファイル名・タグ名の月日の表示を0でパディングするように修正
- WindowsのExplolerでmp3の再生時間が正しく表示されない問題に対処するため、ffmpegのエンコードオプションに’-ar 44100 -ab 64k’を明示的に追加
- ダウンロード済みのファイルが存在する場合、ダウンロードが不完全かどうかをファイルサイズでチェックして、サイズが足りない場合は再ダウンロードする処理を追加
- MacとWindows上でダウンロードする際に、ダウンロードフォルダ名に週番号を付与する処理を追加。
※PC上でのダウンロードはNASの自動処理がトラブルを起こしている場合の代替手段になります。ダウンロード後にNASにファイルを移動しますが、週ごとに正しくダウンロードできているかどうかを確認する必要が出てくることと、複数週分のファイルが一つのフォルダにまとまってしまうと確認と移動が大変になります。そこで、ダウンロードフォルダに週番号をつけてファイルが混ざらないようにしています。
スクリプトはリスト’url_kouza_sizes’にセットした講座情報を一つずつ上から下へ処理していくだけなので、プログラミング経験があれば処理内容は理解できると思います。
mp3のタグ名やダウンロード時のフォルダ構成やファイル名など、それぞれの要望に合わせて細かな調整もスクリプトの当該部分を変更するだけで、簡単に対応できます。
ダウンロードURLのフォーマットが変わったりlistdataflv.xmlのパスが年度ごとに変わったりすることがありますが、その場合はCaptureStream2のソースコードやNHK.htaのコメントなどからURLを探し当ててスクリプトを変更できさえすれば、ツールのアップデートを待たずにダウンロードできるようになります。
ファイルがダウンロード済みの場合はダウンロードをスキップするようにしているので、何度実行してもダウンロードは一回のみになります。この仕様により、毎日定時に自動実行するようにすれば、ネットワークトラブルなどでダウンロードに失敗した場合でも週内はリトライがかかるため、ダウンロード漏れの可能性を減らすことができます。
Synology NASで自動ダウンロードする
Synology NASは単体でpythonとffmpegを実行することができるので、NAS単体で上記のスクリプトを動作させることができます。
また、SynologyのNASはスケジュール実行が簡単に設定できるので、定期的なダウンロード処理をする手段として使わない手はありません。
しかし、Synologyにデフォルトでインストールされているffmpegのバージョンは4.1.3と大変古く、上記の方法によるダウンロードができません。このため、有志が配布しているffmpegを下記手順でインストールする必要があります。(2022年11月16日現在では4.4.2がインストールされます)
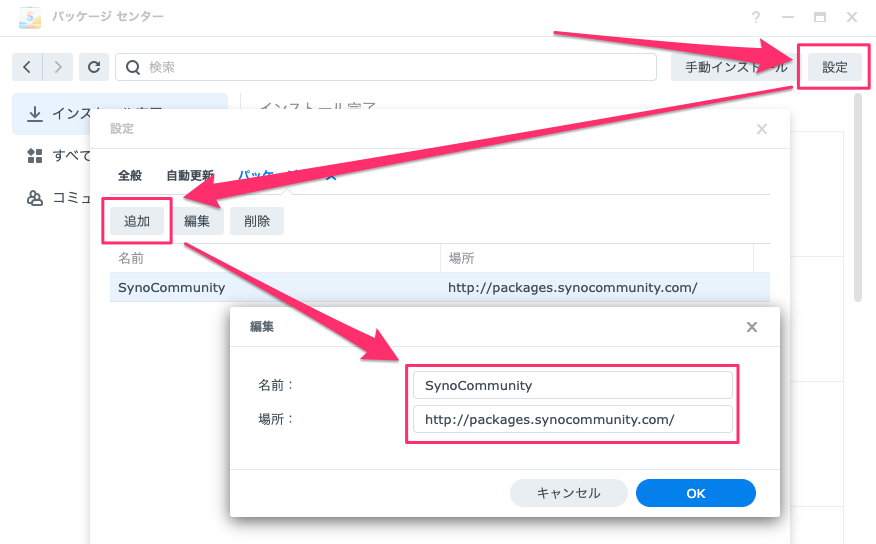
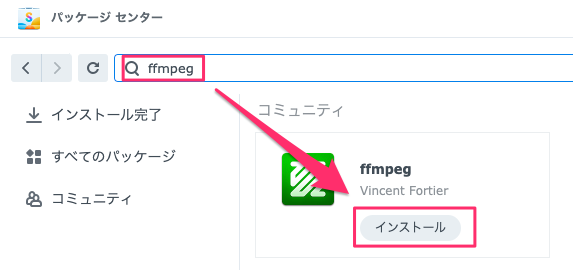
なお、このときにインストールされるffmpegのパスは /volume1/@appstore/ffmpeg/bin/ffmpeg になり旧版が上書きされるわけではないので、パスを指定せずにffmpegを呼び出してもここでインストールしたffmpegは起動しません。このため、pythonスクリプトから新たにインストールしたffmpegを起動する場合は絶対パスで指定する必要があります。
ffmpegのデフォルトパスを変更する方法もありますが、スクリプト内で絶対パスで指定するほうがNASシステムへの影響がなく、システムアップデート時に修正が上書きされて修正を元に戻されて動作しなくなるトラブルもないので安全です。
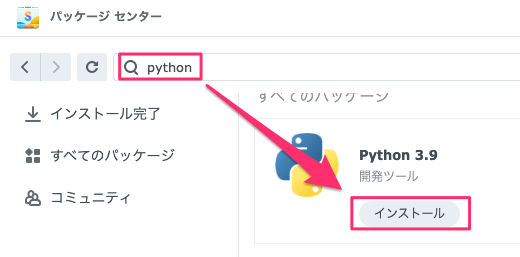
Pythonはパッケージセンターのものを指定してインストールすればいいです。バージョンは3.9以上であれば問題はないと思います。
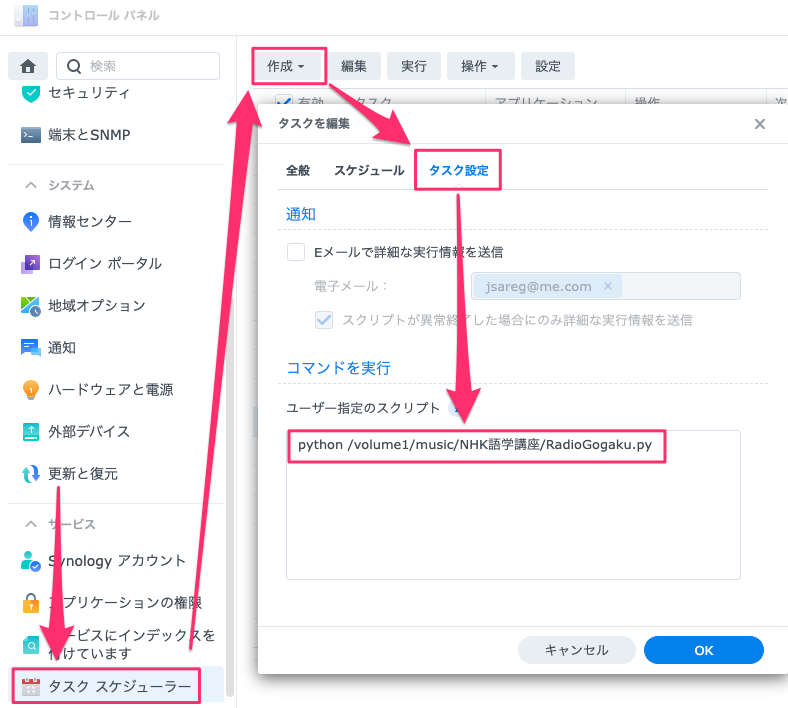
あとはコントロールパネルにあるタスクスケジューラーで定期実行するように設定すれば毎週自動的にダウンロードされるようになります。
正しくダウンロードされたかをチェックする
自動ダウンロード処理が実行されても、自宅のネットワークトラブルやXML仕様の変更など、様々な要因でダウンロードに失敗する可能性があります。
ダウンロード対象の番組が1−2本程度で、毎週聞いているのであれば週内にダウンロード失敗に気づき再ダウンロードもできますが、多数の番組をダウンロードしているとチェックの手間も無視できません。
番組によらずファイルサイズは再生時間に比例するので、Everythingを使うなどして最新のダウンロードファイルのファイルサイズを一覧できれば、ファイルサイズがすべて同じかどうかを確認するだけで大丈夫です。ただし、確認のたびにPCを起動しNAS上のフォルダを開いてファイルサイズを確認するというのは手順が多く、毎週定期的に行う作業手順としては少々煩雑です。
私の場合はNASに付属している音楽再生ソフト(Synologyの場合はAudioStation)のスマートプレイリスト(条件にあった曲を自動で検索してリストアップ)を利用して、スマホとPCのブラウザ上でダウンロードチェックできるようにしています。
リスト表示の条件は以下のように設定しています。
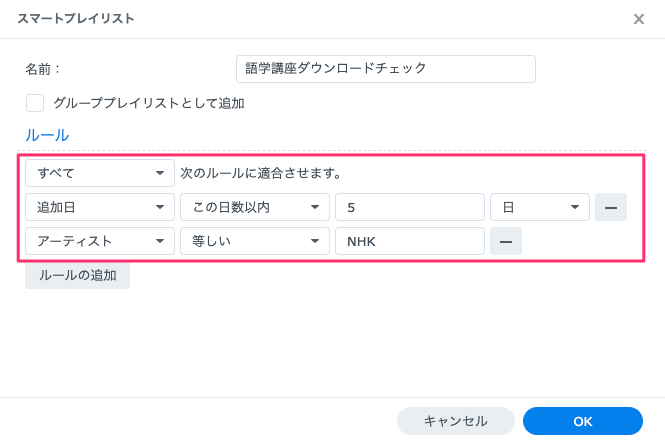
SynologyのAudioStationにはファイルサイズを表示する機能はないので、ファイル再生時間が全て15分になっているかどうかでダウンロードが正しく行われているかを確認しています。
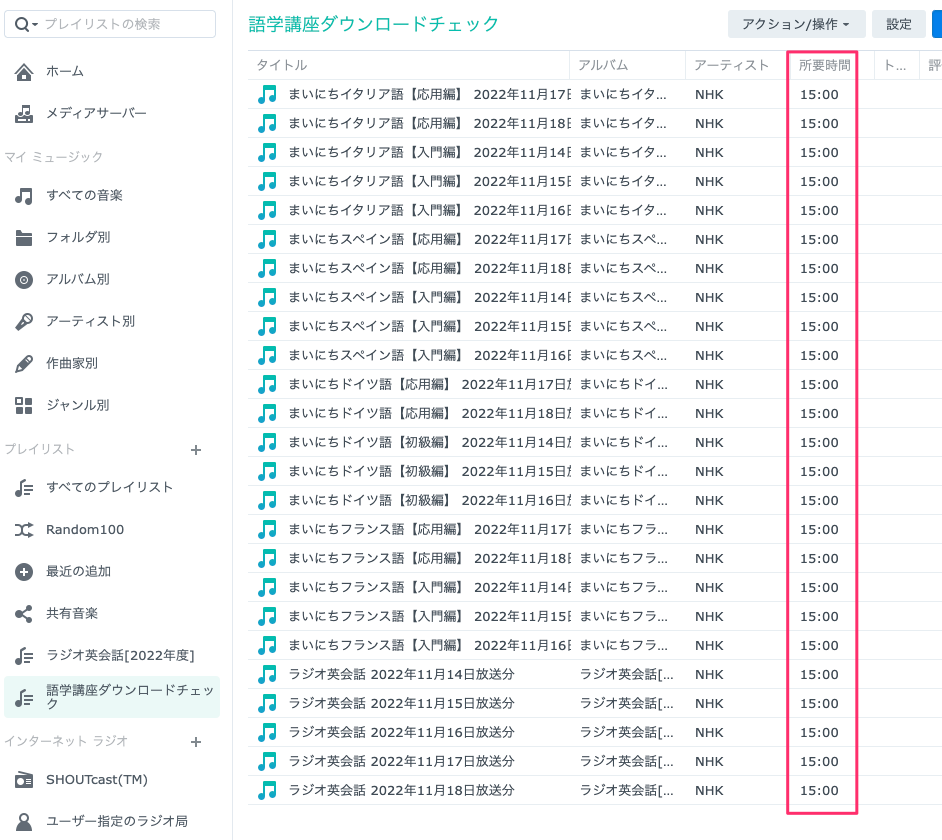
SynologyのAudioStationはスマホアプリもあり、このプレイリストを表示してダウンロードチェックをしたあと、このプレイリスト上でファイルをスマホにダウンロードする手順でダウンロードチェックをしてます。
参考になれば幸いです。
これまでラジオ英会話は録音していましたが、ここで説明されている通りにmp3ファイルをダウンロードできるようになりました。ありがとうございます。
コメントありがとうございます。お役に立てたようで何よりです。
おかげさまで、現在、「ラジオ英会話」と「英会話タイムトライアル」のファイルは取得していますが、「ニュースで学ぶ現代英語」のファイルも取得できればと思っています。プログラムの中の
https://www.nhk.or.jp/gogaku/st/xml/english/gendai/listdataflv.xml
の”gendai”を置換する必要があるようです。
助けていただければ幸いです。
調べてみたところ、NHK.htaの作者様の発言の中に非対応という文言がありました。このことから上記のURLでは対応できない手順でダウンロードするURLを取得する必要がありそうです。
現状簡単にその情報に辿り着けず、解決方法の確定と実装には時間と手間がかかりそうです。
お役に立てず申し訳ございませんが、ご容赦ください。
「ニュースで学ぶ現代英語」のダウンロード用スクリプトを書きました。下記ページをご参照ください。
https://simplelife.pgw.jp/it/nhk_radio_gogaku_kouza_json/
よろしくお願いいたします。
ニュースで学ぶ現代英語
xmlではなく、jsonファイルからダウンロードするように
はできませんか?
本ページをご覧いただきありがとうございます。XMLでもJSONでもダウンロードに必要な要素が拾えれば対応は可能かと思います
ただ、JsonをダウンロードするURLが見つかりません。下記URLがそのURLであるとのページを見つけましたが、リンク切れとなっておりました。
https://www.nhk.or.jp/gogaku/gendaieigo/json/news.json
お手数ですが、URLをご存知であれば教えていただければ幸いです。よろしくお願いします。
これは役に立ちますかね?
https://www.nhk.or.jp/radioondemand/json/7512/bangumi_7512_01.json
リンク情報ありがとうございます。
ダウンロードして確認したところ、ダウンロードに必要な情報が取得できることがわかりましたので、早速pythonスクリプトを書き、WindowsとNASでダウンロードできるようになりました。1つのスクリプトにXML/JSON対応版を混在するとコードが複雑になるので、新たにスクリプトを書いてページも新しく書き起こしました。
https://simplelife.pgw.jp/it/nhk_radio_gogaku_kouza_json/
参考になれば幸いです。
よろしくお願いいたします。
とても参考になりました。ありがとうございました。よろしければ2024年度の最新に対応更新できないでしょうか。自力でやっているのですが中々難しくて…
掲載しているPythonスクリプトは現在のXMLフォーマットをNHK側で維持している限り自動で新年度対応されます。
来週の切り替わりで対応していないようであれば対応したいと思います。
よろしくお願いします。
ありがとうございます。そうなんですね。
https://www.nhk.or.jp/gogaku/st/xml/english/kaiwa/listdataflv.xml
が昨年度のものなのでダメだと思っていました。
あと関係ないですが、先のコメントの名前を匿名希望に変えていただけるとありがたいです。
2022->2023年度では特に変更はなかったので、2024年度も変更はないものと期待しています。
お名前は変更いたしましたので、ご確認ください。
よろしくお願いいたします。
2024年度もきちんと動作することが確認できました。環境はFreebsdのPython3.9です。ありがとうございました。
確認のご連絡ありがとうございます。
こちらでもSynology NAS上で無事ダウンロードができることを確認できました。
時間ができ次第、現在コメントアウトしているものもダウンロードできるか確認してみようと思います。
JSONデータによるダウンロード用スクリプトを作成しました。こちらでもラジオ英会話などNHKラジオ講座の全放送のダウンロードができるようです。XML版と違いJSONは即日ダウンロードリンクが拾えますので、毎日自動ダウンロード処理を行うことで放送に遅れることなくいつでもラジオ講座を聞くことができそうです。
https://simplelife.pgw.jp/it/nhk_radio_gogaku_kouza_json/
ご参考まで。
ヨーロッパ系語学講座 まいにちXXX語
jsonの URLが初級編と応用編でヨーロッパ系語学講座が
一つになりました
xmlもヨーロッパ系語学講座 まいにちXXX語がひとつに?
2024/04/08現在、今まで使用していたXML形式のダウンロードスクリプトで引き続き正常にダウンロードできているようですので、スクリプトはこのまま維持させていただきます。
よろしくお願いいたします。
テレビ、テキストは初級編。
語学アプリだと入門編どうなってるんでしょう?
このスクリプトは?
コメントありがとうございます。
本スクリプトではJSONデータに従い「初級編」で表記しています。
よろしくお願いします。
私にはこのスクリプトxmlは入門編となって見えてますが?
JSON版の方のご指摘と勘違いしていました。
ご指摘の部分は修正しておきました。
よろしくお願いします。
全講座のJSONリンクを入手できましたので、スクリプトをアップデートしました。ご指摘にあったようにヨーロッパ系言語の語学講座のURLが一つに纏まりましたが、同じフォルダにダウンロードすると分類が手間なので、自動で別フォルダに振り分ける処理を追加しました。
https://simplelife.pgw.jp/it/nhk_radio_gogaku_kouza_json/
ご参考まで。
ボキャブライダーのXMLデータは2024年度1年分が既に登録されています
データが多いので2024年度だけダウンロードできるようにするとか?
それにダウンロードurlですが
2022年11月11日以前は/mp4/がつきますが11月14日以降は/mp4/はつきません
ボキャブライダーについては過去7日間の放送のみをダウンロード対象にするように処理を追加してみました。
年度表記対応などややこしい処理が入るため、テストはしてはいるものの年を跨いだ際の日付処理が期待通りに処理されるかは実際にその日になってみないとわかりません。まずはこれでFixとし、年始に問題が発生したらその際に対応してみたいと思います。
よろしくお願いします。
試してみたところ、NASでmp3を取得できました。
非常に分かりやすい内容でした。ありがとうございます。
お試しいただき、その結果と感想のご連絡感謝いたします。
「ニュースで学ぶ現代英語」がJSONしか対応していないことと放送後即日ダウンロード可能になること、また取得できる情報がXMLよりのJSONの方が豊富であることから、JSON版を主にアップデートしていこうと思いますので、そちらをご利用いただければと思います。
よろしくお願いいたします。
ご案内いただいたJSON版に差し替えました。
らじれこなど、Windowsのクライアントソフトで音声データを入手できることは分かっていたのですが、NASで自動取得できて本当に重宝しています。大変ありがとうございます。
なお、「NHK語学講座」のアプリで配信されるデータと比べて、mp3はやや音質の点が気になりました。データサイズとのトレードオフになりますが、AACも取得してみました。
“`python
f” -ar 44100 -ab 64k -c:a aac” \
“`
ファイルサイズはmp3比で3倍程度になるので、実用的かというと微妙なところでした。しばらくはこちらを利用してみます。
本記事がお役に立てたようで嬉しいです。
公開当初はダウンロードする際のファイル形式はAACとしていましたが、スマホでダウンロードする際のダウンロードサイズが大きくなることと、聞く時は電車などのノイズの多いところで聞くので音質よりもサイズを重視しました。
スクリプトはあくまで私が欲しい機能を実装しておりますので、ご利用の際にはご自分の要求に合うように改造していただければと思います。
よろしくお願いいたします。
9月になってからうまく動作しなくなりました。
何か情報ありましたらよろしくお願いいたします。
XML対応版については一部番組がダウンロードできないなど制限事項が多くなってきたので、現在は下記JSON版をメンテしています。
https://simplelife.pgw.jp/it/nhk_radio_gogaku_kouza_json/
機能や使い方はXML版と変わりませんので、JSON版のスクリプトに入れ替えていただけれ大丈夫かと思います。
よろしくお願いいたします。
ありがとうございました。JSON版でうまくいきました。FreeBSD14とPython 3.9.18の環境です。
無事動作したとのこと、また動作環境のご連絡もありがとうございます。
JSON版の方は引き続きメンテナンスを続けていこうと思いますので、不具合などありましたらそちらの記事にコメントいただければ幸いです。
よろしくお願いいたします。
https://www.nhk.or.jp/gogaku/st/xml/english/gendaieigo/listdataflv.xml
ニュースで学ぶ「現代英語」
URLのご連絡ありがとうございます。
ただ、本記事初めに記載しましたように、XML版はダウンロードができなくなっている語学講座があることと、JSON版の方がその日のうちにダウンロードが可能になるなど、XML版の機能を包括しています。現在はJSON版のみをアップデートしていますので、JSON版への切り替えをお願いいたします。すでにXML版をセットアップしている場合はスクリプトを上書きするだけで動作すると思います。
よろしくお願いいたします。